创业者,主要项目是面包多,此外做了哄哄模拟器等小爆款。居住在北京。
RSS 地址: https://greatdk.com/feed
请复制 RSS 到你的阅读器,或快速订阅到 :
2024-01-22 11:40:31
24 小时涌入超过 60 万用户,消耗了大模型十几亿 token,发生 2000 万次对话,而事情的起源却是一次吵架。
 很久以来,我已经体验过太多的「聊天AI」了,无论是通用且强大的 ChatGPT还是专注于角色扮演的 Character.ai,他们都很强,但对我来说还是有一个小遗憾:他们只是聊天。
在聊天之外,如果能再加上数值系统和各种判定,那么就可以做出更游戏化的体验,此时大模型不仅负担起了聊天的任务,也会负担起基于聊天来做数值规则的任务,这在大模型出现之前,是不可能的,数值系统也都是按照既定规则来写死的。
开发哄哄模拟器,是我的一次实验,我发现我确实可以让模型输出拟人的回复,也能做好数值的设计。
App 上线之后,我照例在能发的几个地方发了一下,虽然有些响应,但最终用户就几百个人,因为是我业余做的,所以我也没在意,就放在那里没管了。
上周,公司内开始做一些新项目的选型,我也凑过去看了一眼,然后突然意识到,我经常被人误认为是全栈工程师,但其实我连 react 都不会写,这实在脸上无光,于是我准备开始学习 react,我学习新语言一般会直接从项目上手,所以我又一次想到了哄哄模拟器,并准备写一个网页版,来完成我的 react 入门。
学习新语言和开发新产品的过程已经和往日大不相同,在大模型加持的各种代码助手辅助下,我基本上很快就稀里糊涂的写完了第一个版本,并上线了。
很久以来,我已经体验过太多的「聊天AI」了,无论是通用且强大的 ChatGPT还是专注于角色扮演的 Character.ai,他们都很强,但对我来说还是有一个小遗憾:他们只是聊天。
在聊天之外,如果能再加上数值系统和各种判定,那么就可以做出更游戏化的体验,此时大模型不仅负担起了聊天的任务,也会负担起基于聊天来做数值规则的任务,这在大模型出现之前,是不可能的,数值系统也都是按照既定规则来写死的。
开发哄哄模拟器,是我的一次实验,我发现我确实可以让模型输出拟人的回复,也能做好数值的设计。
App 上线之后,我照例在能发的几个地方发了一下,虽然有些响应,但最终用户就几百个人,因为是我业余做的,所以我也没在意,就放在那里没管了。
上周,公司内开始做一些新项目的选型,我也凑过去看了一眼,然后突然意识到,我经常被人误认为是全栈工程师,但其实我连 react 都不会写,这实在脸上无光,于是我准备开始学习 react,我学习新语言一般会直接从项目上手,所以我又一次想到了哄哄模拟器,并准备写一个网页版,来完成我的 react 入门。
学习新语言和开发新产品的过程已经和往日大不相同,在大模型加持的各种代码助手辅助下,我基本上很快就稀里糊涂的写完了第一个版本,并上线了。
 哄哄模拟器网页版上线之后,我也发在了几个地方,包括我的微博,即刻,X,还有V2ex,但说实话,都反响平平,虽然我暗自感觉不应该感兴趣的人这么少,但考虑到也没投入啥成本,还顺便学了新东西,倒也不觉得难受。
哄哄模拟器网页版上线之后,我也发在了几个地方,包括我的微博,即刻,X,还有V2ex,但说实话,都反响平平,虽然我暗自感觉不应该感兴趣的人这么少,但考虑到也没投入啥成本,还顺便学了新东西,倒也不觉得难受。
 睡前我最后看了一眼数据,即时在线人数是 2000
第二天早上起床后,我立刻查看数据,发现在线人数已经飙到了 5000,日活用户到了接近 10 万,在短暂的陶醉后,我立马意识到大事不妙,哄哄模拟器背后使用的大模型基于 GPT,我调用了 openai 的 gpt3.5 接口,这里的成本是0.0015美元/1000个token,而一个晚上我就跑了一亿的 token,为此我要付出的是 150 美元
睡前我最后看了一眼数据,即时在线人数是 2000
第二天早上起床后,我立刻查看数据,发现在线人数已经飙到了 5000,日活用户到了接近 10 万,在短暂的陶醉后,我立马意识到大事不妙,哄哄模拟器背后使用的大模型基于 GPT,我调用了 openai 的 gpt3.5 接口,这里的成本是0.0015美元/1000个token,而一个晚上我就跑了一亿的 token,为此我要付出的是 150 美元
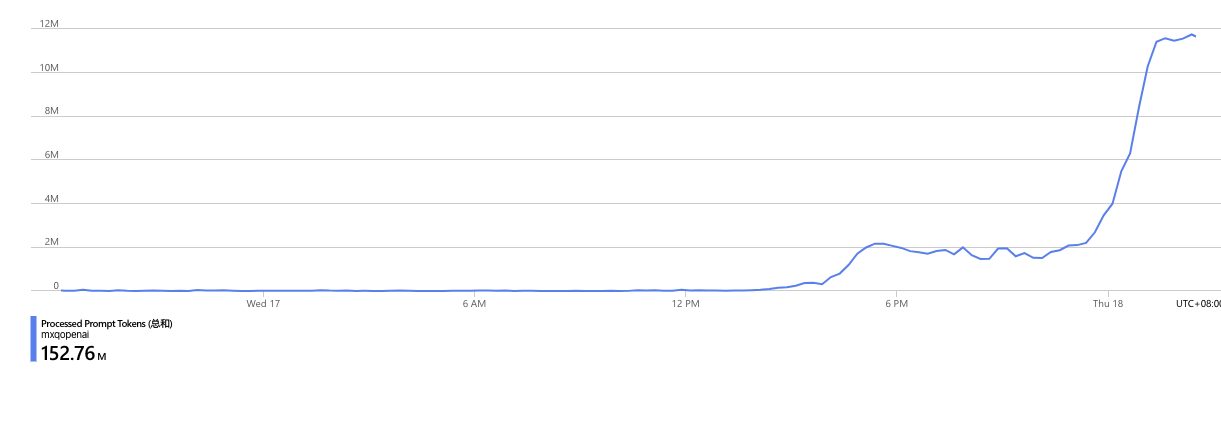 但这只是一个晚上(还包括了大家都在睡觉的凌晨)的数据,如果按照这样的用量趋势持续一天,那我要付出的成本就会是上千美元了。
对于一个很接近玩具且做的很简陋的项目而言,每天几千美元的成本是不可承受之重。与此同时,用户量还在不断增加,几乎每刷新统计页面,就会新增数百人。
但这只是一个晚上(还包括了大家都在睡觉的凌晨)的数据,如果按照这样的用量趋势持续一天,那我要付出的成本就会是上千美元了。
对于一个很接近玩具且做的很简陋的项目而言,每天几千美元的成本是不可承受之重。与此同时,用户量还在不断增加,几乎每刷新统计页面,就会新增数百人。
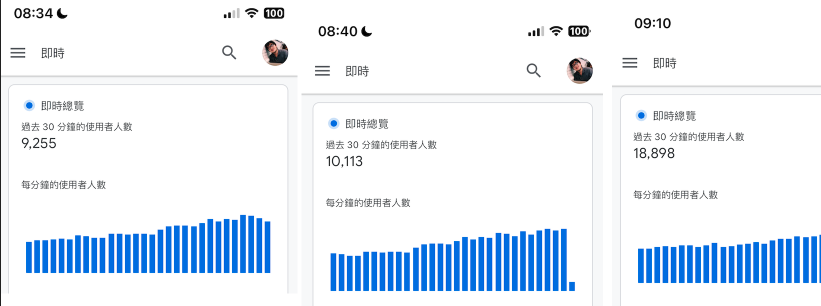 我一开始还在新高峰出现时截图,后来就懒得截了,我把精力放到了更紧迫的事情上面:找出用户从哪来,想办法变现,减少 token 消耗。
在网页上,我放置了联系开发者按钮,然后引导到了我的微博,半小时后,开始陆续有新的关注者评论,绝大部分都表示来自 QQ 空间和 QQ 群
我一开始还在新高峰出现时截图,后来就懒得截了,我把精力放到了更紧迫的事情上面:找出用户从哪来,想办法变现,减少 token 消耗。
在网页上,我放置了联系开发者按钮,然后引导到了我的微博,半小时后,开始陆续有新的关注者评论,绝大部分都表示来自 QQ 空间和 QQ 群
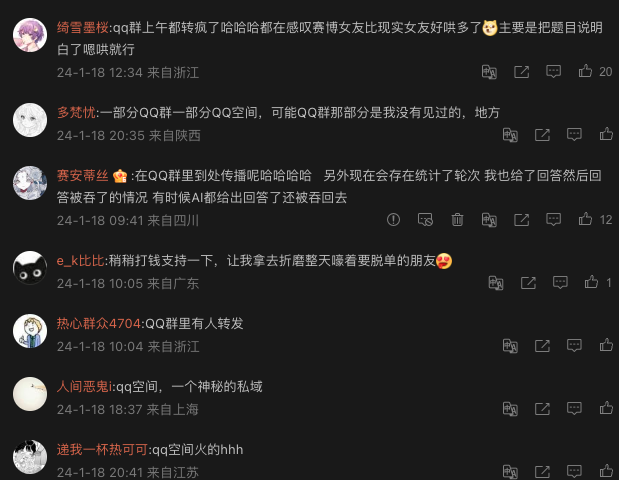 我和其中一些用户聊了一下,大概找到了流量来源,起先应该是一个来自QQ空间的帖子介绍了哄哄模拟器,这篇帖子获得了数千次转发,既而又被发到了无数QQ群,并在群友中传播。
这也解答了为啥我一开始找不到流量来源的原因,QQ空间和QQ群都是比较封闭的生态,也无法追踪链接跳转的来源,这里面没有 KOL,传播节点也极其分散。
我和其中一些用户聊了一下,大概找到了流量来源,起先应该是一个来自QQ空间的帖子介绍了哄哄模拟器,这篇帖子获得了数千次转发,既而又被发到了无数QQ群,并在群友中传播。
这也解答了为啥我一开始找不到流量来源的原因,QQ空间和QQ群都是比较封闭的生态,也无法追踪链接跳转的来源,这里面没有 KOL,传播节点也极其分散。
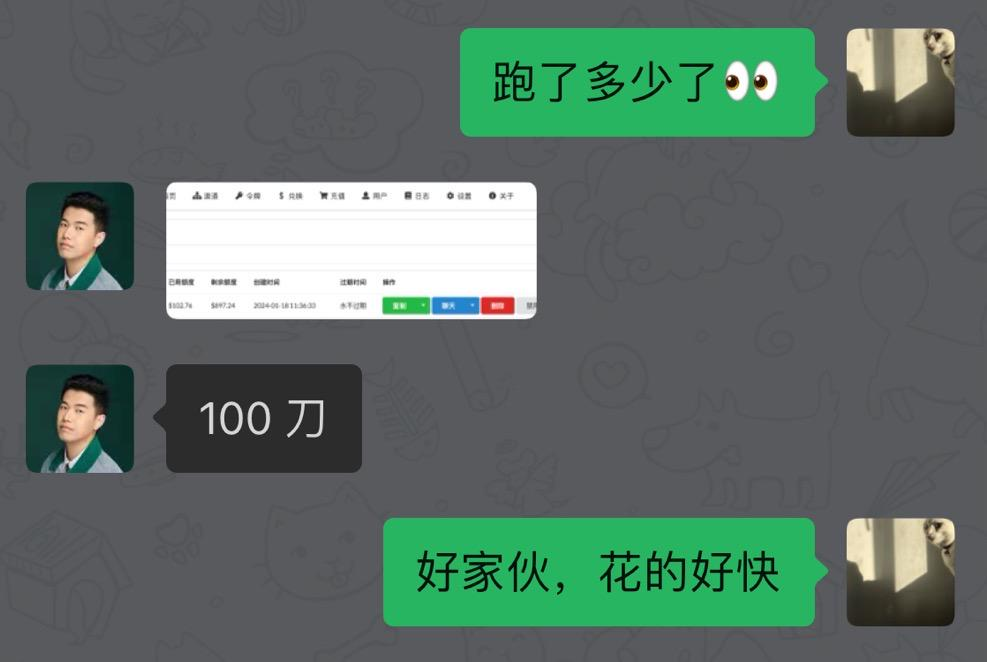 token 在两边都极速消耗,很快就在伯昊的账号下就跑了 100 美金的额度。而我自己那边我已经不想去看了。
缓一口气后,我开始尝试用其它模型替代 GPT ,这虽然在成本上不一定更划算,但至少有一些新的可能性,跑了几个差强人意的开源模型后,我尝试了 Moonshot,发现效果还可以,与此同时我刚好前不久加了月之暗面公司负责 API 的同学,于是我心一横,厚着脸皮直接向对方发了消息
token 在两边都极速消耗,很快就在伯昊的账号下就跑了 100 美金的额度。而我自己那边我已经不想去看了。
缓一口气后,我开始尝试用其它模型替代 GPT ,这虽然在成本上不一定更划算,但至少有一些新的可能性,跑了几个差强人意的开源模型后,我尝试了 Moonshot,发现效果还可以,与此同时我刚好前不久加了月之暗面公司负责 API 的同学,于是我心一横,厚着脸皮直接向对方发了消息
 Moonshot 同学很快拉了群和我对接,并慷慨的让我「先试试」,于是我开始进行调试,然后将1/5的模型调用量切给了 Moonshot ,我采集用户行为数据,观察使用不同模型时,进入下一步操作的比例,在接入 Moonshot 大约1小时后,我看了数据,发现和我之前使用的 gpt3.5 相差不大,于是我将切给 Moonshot 的用量逐渐提高。
其实我们也没有谈太多的条件,Moonshot 让我免费使用模型,我肯定也要在页面展示 Moonshot 的品牌信息,但除此之外,要有多少曝光?点击多少次?给我多少token?其实我们都没有谈,在跟对方交流的时候,我感觉双方都抱着开放的心态,像面对一场有趣的实验而不是什么商业合作,我们一起兴致勃勃的观察模型表现,以及用量的波动。
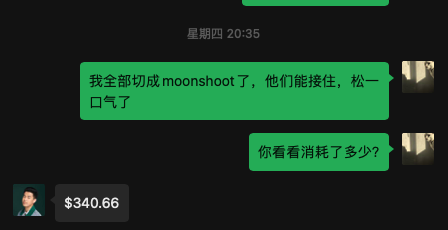
傍晚时,经过多次调试,也确认了这个调用量级没问题后,我将模型调用量全量切到了 Moonshot,此时我问了伯昊,他那边的成本消耗,最终定格到了 340 美元,伯昊没收我钱,而我将用一顿饭回报这次帮忙。
Moonshot 同学很快拉了群和我对接,并慷慨的让我「先试试」,于是我开始进行调试,然后将1/5的模型调用量切给了 Moonshot ,我采集用户行为数据,观察使用不同模型时,进入下一步操作的比例,在接入 Moonshot 大约1小时后,我看了数据,发现和我之前使用的 gpt3.5 相差不大,于是我将切给 Moonshot 的用量逐渐提高。
其实我们也没有谈太多的条件,Moonshot 让我免费使用模型,我肯定也要在页面展示 Moonshot 的品牌信息,但除此之外,要有多少曝光?点击多少次?给我多少token?其实我们都没有谈,在跟对方交流的时候,我感觉双方都抱着开放的心态,像面对一场有趣的实验而不是什么商业合作,我们一起兴致勃勃的观察模型表现,以及用量的波动。
傍晚时,经过多次调试,也确认了这个调用量级没问题后,我将模型调用量全量切到了 Moonshot,此时我问了伯昊,他那边的成本消耗,最终定格到了 340 美元,伯昊没收我钱,而我将用一顿饭回报这次帮忙。
 此时是晚上八点半,我终于吃上了当天的第一口饭。然后我打了一把 FIFA。
此时是晚上八点半,我终于吃上了当天的第一口饭。然后我打了一把 FIFA。
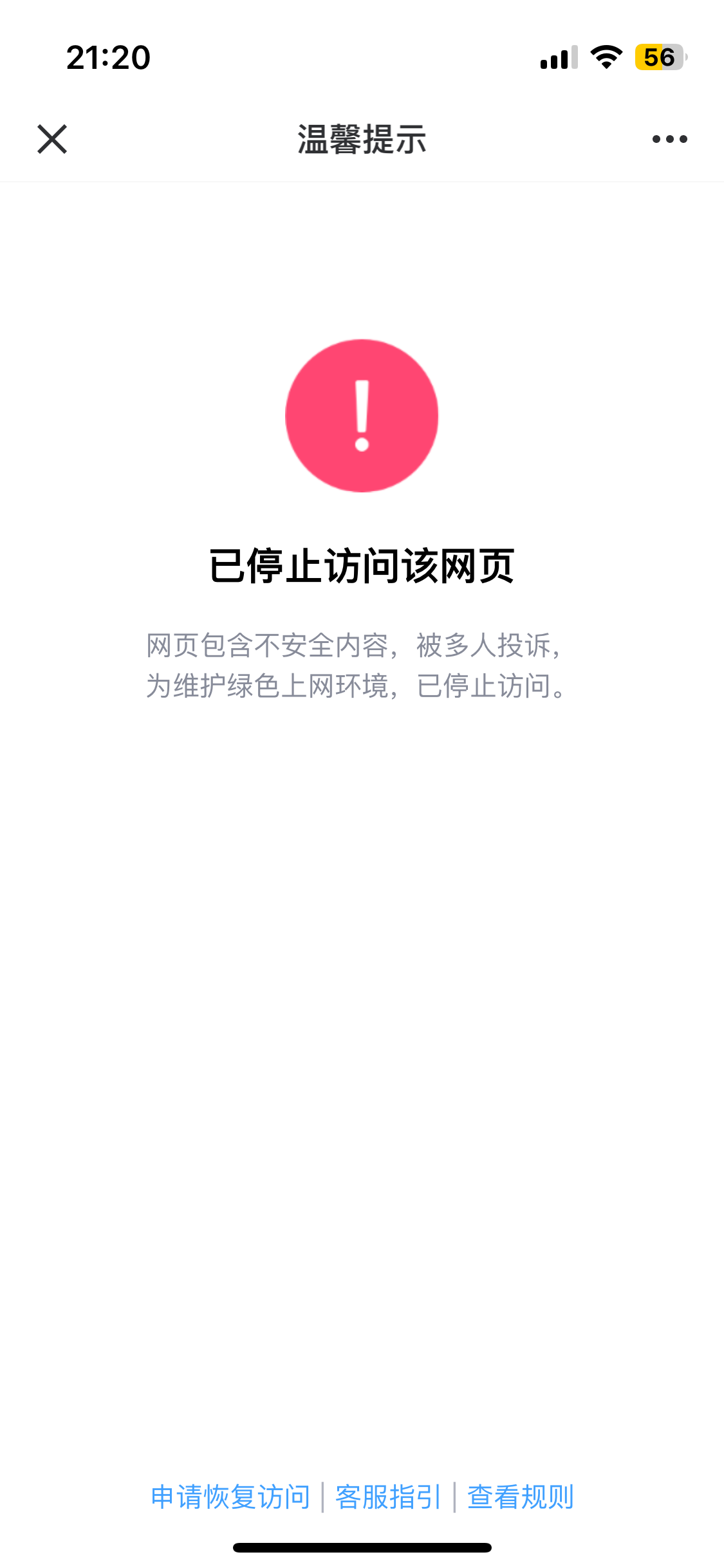 屏蔽发生在最活跃的晚上九点,此时最主要的传播链路——QQ和微信被拦腰斩断,大量抱着好奇心的用户被这个页面挡在了外面,流量以极快速度下滑,最终,当天涌入的用户一共是 68 万——如果没有屏蔽,在这个增速下,我想可能会过百万。
我当晚进行了申诉,第二天早上微信给我解封了,但十小时后,又进行了屏蔽——依然是在晚上最活跃的 9 点,在我申诉后又在次日早上解封,然后晚上继续屏蔽,过去几天这样大概重复了三四次,我也不明白为何要这样做——不给我个痛快,但流量在这样的折腾下迅速降低了。
微信生态素以严格著称,哄哄模拟器的流量激增可能触发了某种机制,也可能是某些用户故意引导模型输出出格内容后举报,让屏蔽不断发生,那个熟悉的画面,让我许多不愉快的记忆涌上心头。
但这一次,我其实没有那么不愉快,一方面我投入的并不多,说实话,这只是我做着玩的项目,同时我也知道,目前的哄哄模拟器,就是一个短期很难有商业回报的产品,它成本极高,而收益却极低——如果我不用非常极端的办法去恶心用户的话。
这样的一个产品,前途其实并不明朗。
屏蔽发生在最活跃的晚上九点,此时最主要的传播链路——QQ和微信被拦腰斩断,大量抱着好奇心的用户被这个页面挡在了外面,流量以极快速度下滑,最终,当天涌入的用户一共是 68 万——如果没有屏蔽,在这个增速下,我想可能会过百万。
我当晚进行了申诉,第二天早上微信给我解封了,但十小时后,又进行了屏蔽——依然是在晚上最活跃的 9 点,在我申诉后又在次日早上解封,然后晚上继续屏蔽,过去几天这样大概重复了三四次,我也不明白为何要这样做——不给我个痛快,但流量在这样的折腾下迅速降低了。
微信生态素以严格著称,哄哄模拟器的流量激增可能触发了某种机制,也可能是某些用户故意引导模型输出出格内容后举报,让屏蔽不断发生,那个熟悉的画面,让我许多不愉快的记忆涌上心头。
但这一次,我其实没有那么不愉快,一方面我投入的并不多,说实话,这只是我做着玩的项目,同时我也知道,目前的哄哄模拟器,就是一个短期很难有商业回报的产品,它成本极高,而收益却极低——如果我不用非常极端的办法去恶心用户的话。
这样的一个产品,前途其实并不明朗。
 值得注意的是,这些用户和我之前做产品所接触的用户完全不同,他们是以大学生,高中生和年轻人组成的,最大比例的年龄区间为16-20岁,我想这可能是一开始我用自己的渠道到处宣传效果并不好的原因,说到底,我已经快 30 岁了,我身边的很多人,也差不多这个年纪,30-40岁的用户,和十几二十岁的用户,感兴趣的点,需求,想法,都有很大不同。
用大模型去做某种更复杂的,更游戏化的聊天体验,能够被人喜欢,至少在年轻人这里,是得到了初步证明的,而之后的问题则是,如何降低成本,如何构建好的商业模式,以及如何拓展到更多的方向上。
值得注意的是,这些用户和我之前做产品所接触的用户完全不同,他们是以大学生,高中生和年轻人组成的,最大比例的年龄区间为16-20岁,我想这可能是一开始我用自己的渠道到处宣传效果并不好的原因,说到底,我已经快 30 岁了,我身边的很多人,也差不多这个年纪,30-40岁的用户,和十几二十岁的用户,感兴趣的点,需求,想法,都有很大不同。
用大模型去做某种更复杂的,更游戏化的聊天体验,能够被人喜欢,至少在年轻人这里,是得到了初步证明的,而之后的问题则是,如何降低成本,如何构建好的商业模式,以及如何拓展到更多的方向上。
2023-12-21 15:17:51
自从几个月前我开始用 AI 改造热量记录工具,发现效果不错之后,我就开始琢磨用 AI 干点更复杂的事情,想必很多人都和我一样,对于网络上铺天盖地的AI毁灭世界论,以及实际上看到最多的例子就是用AI来生成色图和软文的现状,感到有点不满。 在这篇文章,我会讲述一个实际例子,一个试图让 AI 能力和复杂逻辑相结合,成为一个更好用的工具的例子,在这个过程中,我也发现了在面对多维复杂性时——输入的复杂和处理的复杂,即便是最顶尖的 AI 模型也难以解决的问题。
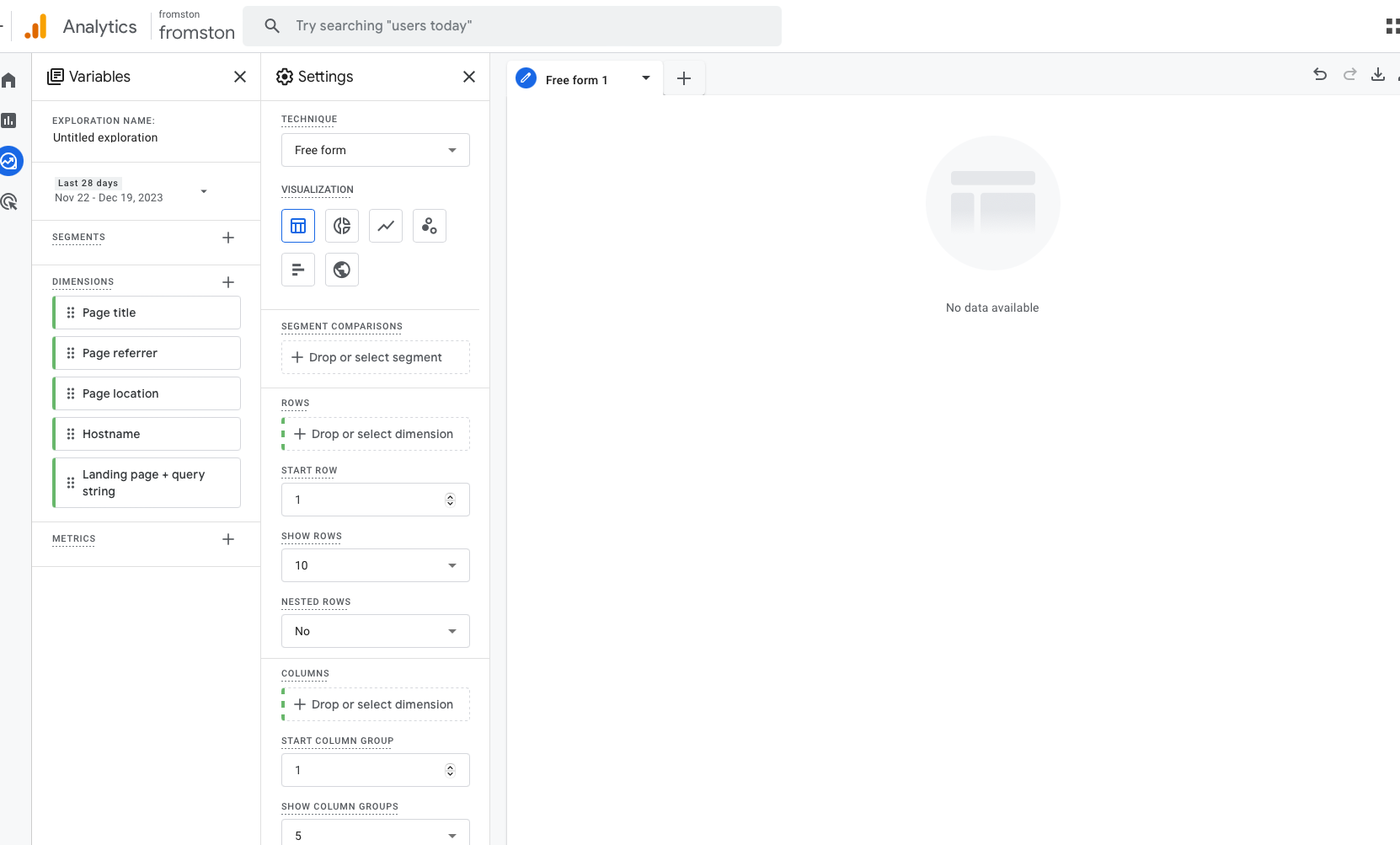
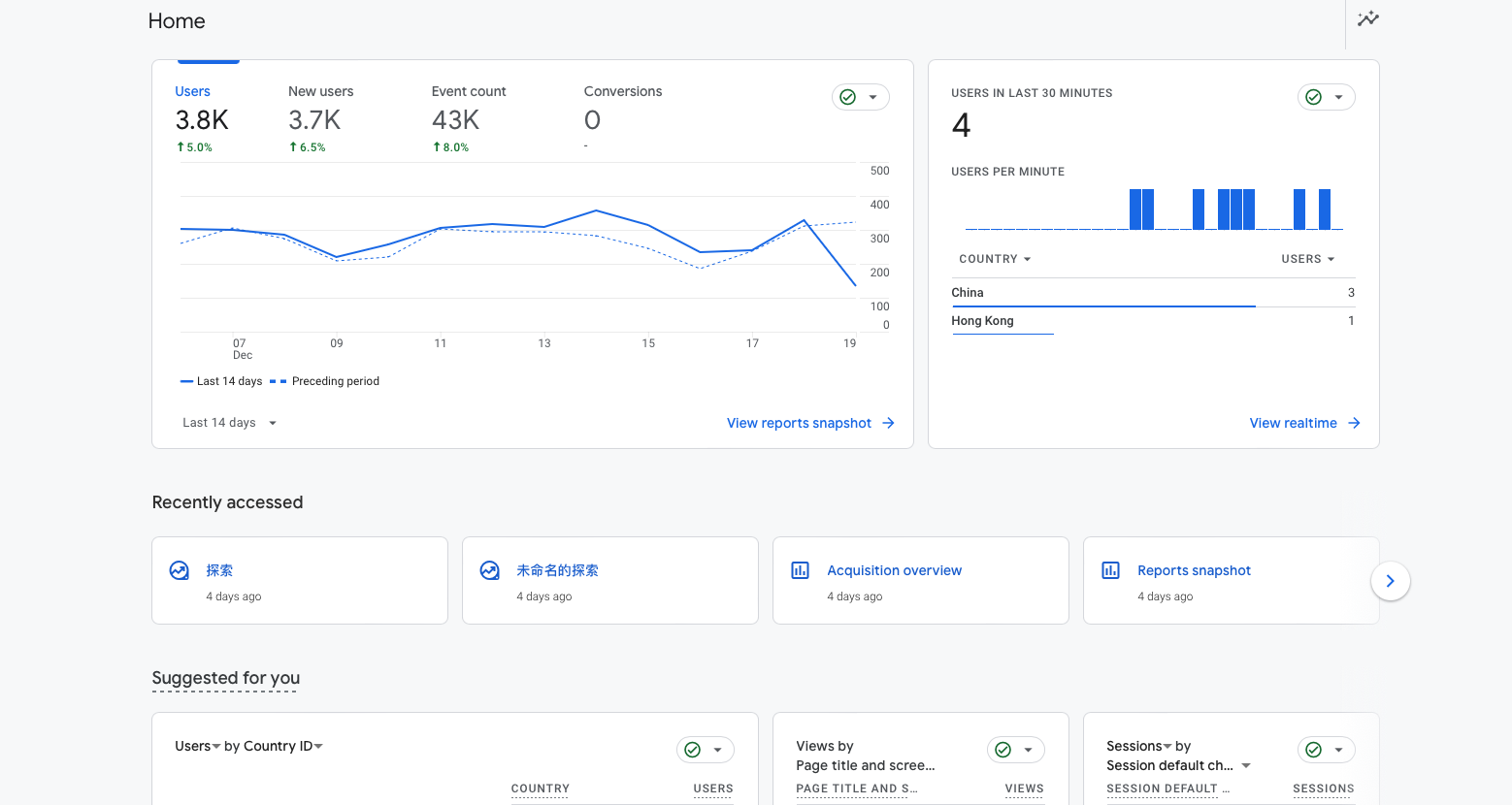 去年,Google 统计进行了改版,升级为了 GA4,这项升级前卫但复杂,很多老用户对新版 Google 统计感到茫然,因为熟悉的东西都没了,想看一些针对性的数据,需要自己创建报告,这又是一个极其复杂的页面:
去年,Google 统计进行了改版,升级为了 GA4,这项升级前卫但复杂,很多老用户对新版 Google 统计感到茫然,因为熟悉的东西都没了,想看一些针对性的数据,需要自己创建报告,这又是一个极其复杂的页面:
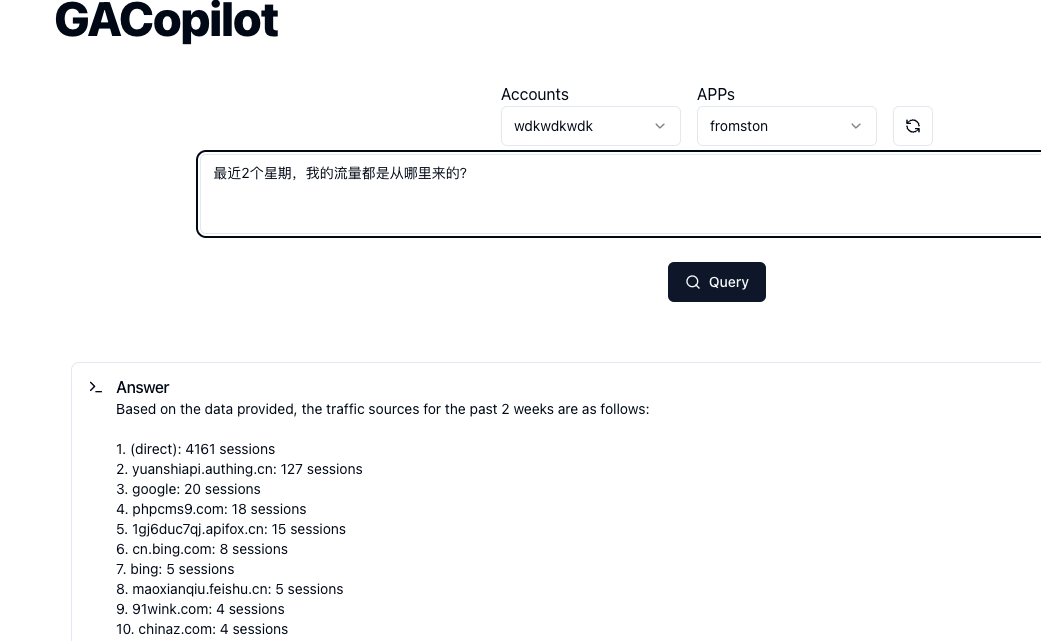
 搭配 GA4,Google 也一起发布了新的 API,调用这些 API,可以从GA 获得任何你想要的数据。因此,当我看到 openai 发布 functions 功能后,我开始意识到,我也许能用AI来改造 GA,让它更人性化一点。
搭配 GA4,Google 也一起发布了新的 API,调用这些 API,可以从GA 获得任何你想要的数据。因此,当我看到 openai 发布 functions 功能后,我开始意识到,我也许能用AI来改造 GA,让它更人性化一点。
 解决这两个问题花费了我大量时间,事实是我其实没办法「解决」,而只是「绕过」了这些问题,我根据 Google 文档,手写了大量规则来修正模型输出的错误。
在这些工作完成后,我终于可以做出一个 demo,它具备这样的能力:你直接描述你想要看到什么数据,然后就能看到,例如:
解决这两个问题花费了我大量时间,事实是我其实没办法「解决」,而只是「绕过」了这些问题,我根据 Google 文档,手写了大量规则来修正模型输出的错误。
在这些工作完成后,我终于可以做出一个 demo,它具备这样的能力:你直接描述你想要看到什么数据,然后就能看到,例如:
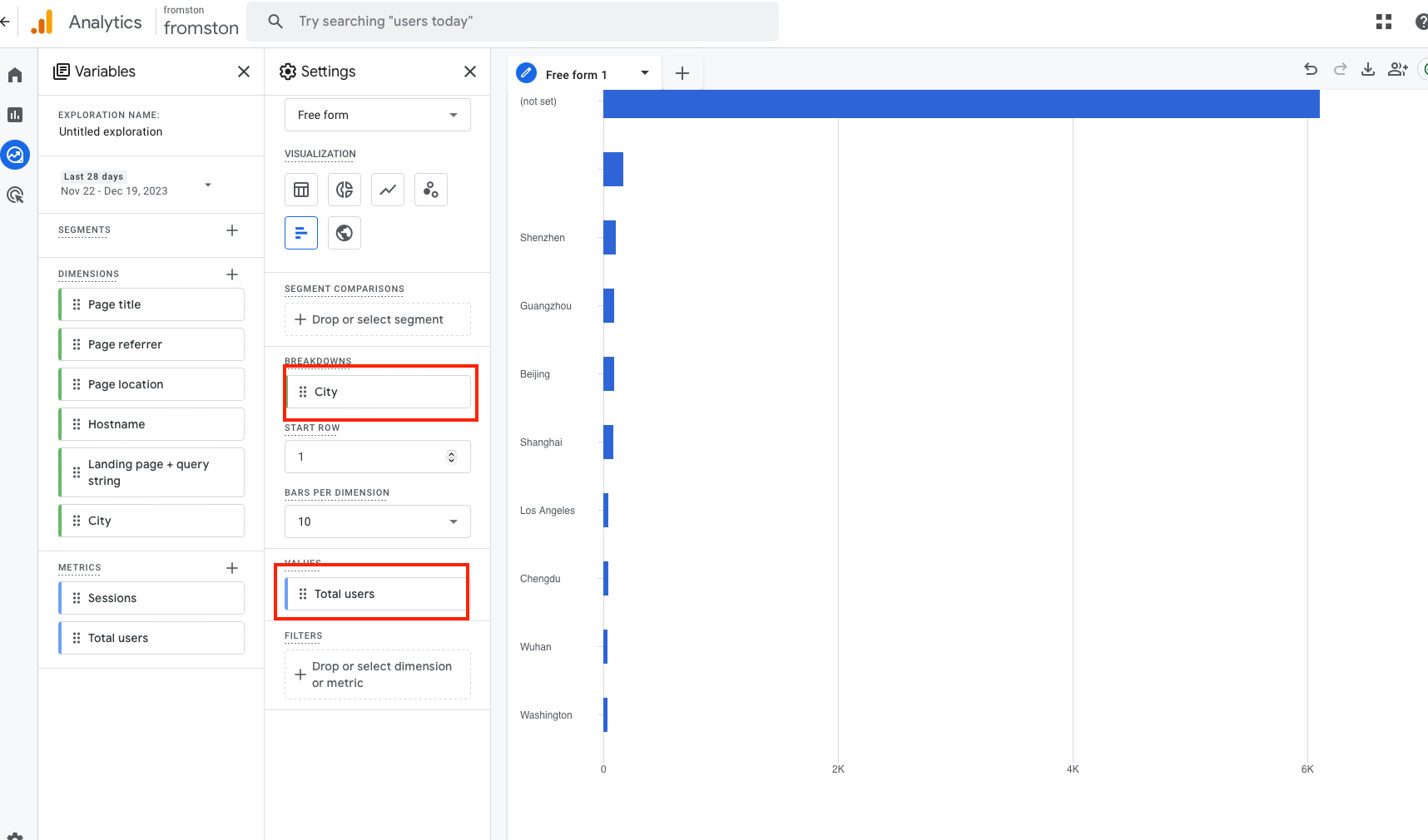
 这个原型产品其实花费了我大量的精力,因为我需要把 Google的 API 全部捋一遍,在这个过程中,我发现了我面对的这些 API 的复杂之处。
GA 的核心 API,叫做 runReport,核心参数主要有两个,一个是维度(dimension),一个是指标(metric),例如,把城市设定为纬度,总用户设定为指标,那么就能获取每个城市的用户:
这个原型产品其实花费了我大量的精力,因为我需要把 Google的 API 全部捋一遍,在这个过程中,我发现了我面对的这些 API 的复杂之处。
GA 的核心 API,叫做 runReport,核心参数主要有两个,一个是维度(dimension),一个是指标(metric),例如,把城市设定为纬度,总用户设定为指标,那么就能获取每个城市的用户:
 GA 支持相当多的纬度和相当多的指标(大几十种)
GA 支持相当多的纬度和相当多的指标(大几十种)
 将这些指标和纬度告诉 gpt,并让其选择合适的,似乎行得通,但马上我们会遇到更复杂一些的情况。
将这些指标和纬度告诉 gpt,并让其选择合适的,似乎行得通,但马上我们会遇到更复杂一些的情况。
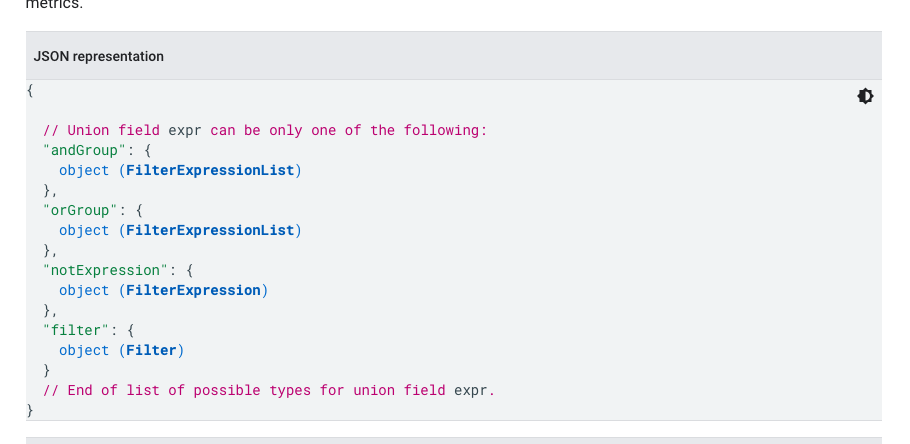 而在和/与/非逻辑之中,还可以设定匹配类型和匹配逻辑,甚至可以写正则。
而在和/与/非逻辑之中,还可以设定匹配类型和匹配逻辑,甚至可以写正则。
 同样在上面的例子中,如果我想知道「北京11月21日有多少用户访问」,除了设定多个纬度之外,更简单的办法则是设置单一维度「日期」,但是将筛选项设定为「城市包含北京」
这是第二层复杂度,即筛选逻辑的控制。
然而,GA 还有一个接口,即 batchRunReports,同时获取多个数据报告,每个报告都包含独立的纬度,指标和筛选,并汇总给你,在面对相当复杂的需求时,往往需要汇总多个报告的数据才能达到目的,而这是第三层复杂度。
在梳理 API 的同时,我也在对 GPT 能力进行实验,我发现即便还不涉及到第一种复杂度,gpt functions已经错误频出,而当我要求其设置多个纬度和参数时,给出的结果更是糟糕——我用的是GPT4,这应该是目前最智慧的大模型。
GPT 似乎只能处理最简单的情况,例如「过去一周的活跃用户」或「最受欢迎的页面有哪些」,这些情况仅下,需要一个纬度和一个指标就能获得合适的数据,但如果我的需求描述的再复杂一点,例如「来自北京的用户最喜欢浏览什么页面」,那么极大概率 GPT 就无法给出正确的参数。
讲道理,如果因为上面的问题,认为 GPT 很愚蠢,那就很愚蠢了,因为我给 GPT 的任务,其实是复杂的数据分析任务,这里面需要:
1.判断用户的问题和需求
2.筛选可能适合的字段和接口使用方式
3.合理的使用这些字段,得到精确的调用参数
这些需求并不简单,能够从 GA 中手动获取到「来自北京的用户最喜欢浏览什么页面」,并且进一步给出一些建议和结论的人,理论上已经可以胜任初级的数据分析师了,拿几千块钱一个月应该问题不大。
同样在上面的例子中,如果我想知道「北京11月21日有多少用户访问」,除了设定多个纬度之外,更简单的办法则是设置单一维度「日期」,但是将筛选项设定为「城市包含北京」
这是第二层复杂度,即筛选逻辑的控制。
然而,GA 还有一个接口,即 batchRunReports,同时获取多个数据报告,每个报告都包含独立的纬度,指标和筛选,并汇总给你,在面对相当复杂的需求时,往往需要汇总多个报告的数据才能达到目的,而这是第三层复杂度。
在梳理 API 的同时,我也在对 GPT 能力进行实验,我发现即便还不涉及到第一种复杂度,gpt functions已经错误频出,而当我要求其设置多个纬度和参数时,给出的结果更是糟糕——我用的是GPT4,这应该是目前最智慧的大模型。
GPT 似乎只能处理最简单的情况,例如「过去一周的活跃用户」或「最受欢迎的页面有哪些」,这些情况仅下,需要一个纬度和一个指标就能获得合适的数据,但如果我的需求描述的再复杂一点,例如「来自北京的用户最喜欢浏览什么页面」,那么极大概率 GPT 就无法给出正确的参数。
讲道理,如果因为上面的问题,认为 GPT 很愚蠢,那就很愚蠢了,因为我给 GPT 的任务,其实是复杂的数据分析任务,这里面需要:
1.判断用户的问题和需求
2.筛选可能适合的字段和接口使用方式
3.合理的使用这些字段,得到精确的调用参数
这些需求并不简单,能够从 GA 中手动获取到「来自北京的用户最喜欢浏览什么页面」,并且进一步给出一些建议和结论的人,理论上已经可以胜任初级的数据分析师了,拿几千块钱一个月应该问题不大。
2023-07-31 01:21:06
就像秋天洄游的鲑鱼,或者冬天南飞的候鸟一样,每到夏天,我就会开始减肥。
我倒并不一定非要减多少,但夏天尽可能瘦一点,已经成了我的一种习惯,这可能是为了在天气变冷时可以放心的吃更多食物,也可能是我内心深处还是有一点对自己身材的包袱,我说不好。
从 6 月开始,我开始有意识的计算每天的食物摄入热量,并制造一个热量缺口。
整个 6 月份下来,我瘦了大约 8 斤,7 月到现在,又差不多瘦了 7 斤,总共有差不多 15 斤,我妈都觉得我瘦了不少(忽略手臂的色差)
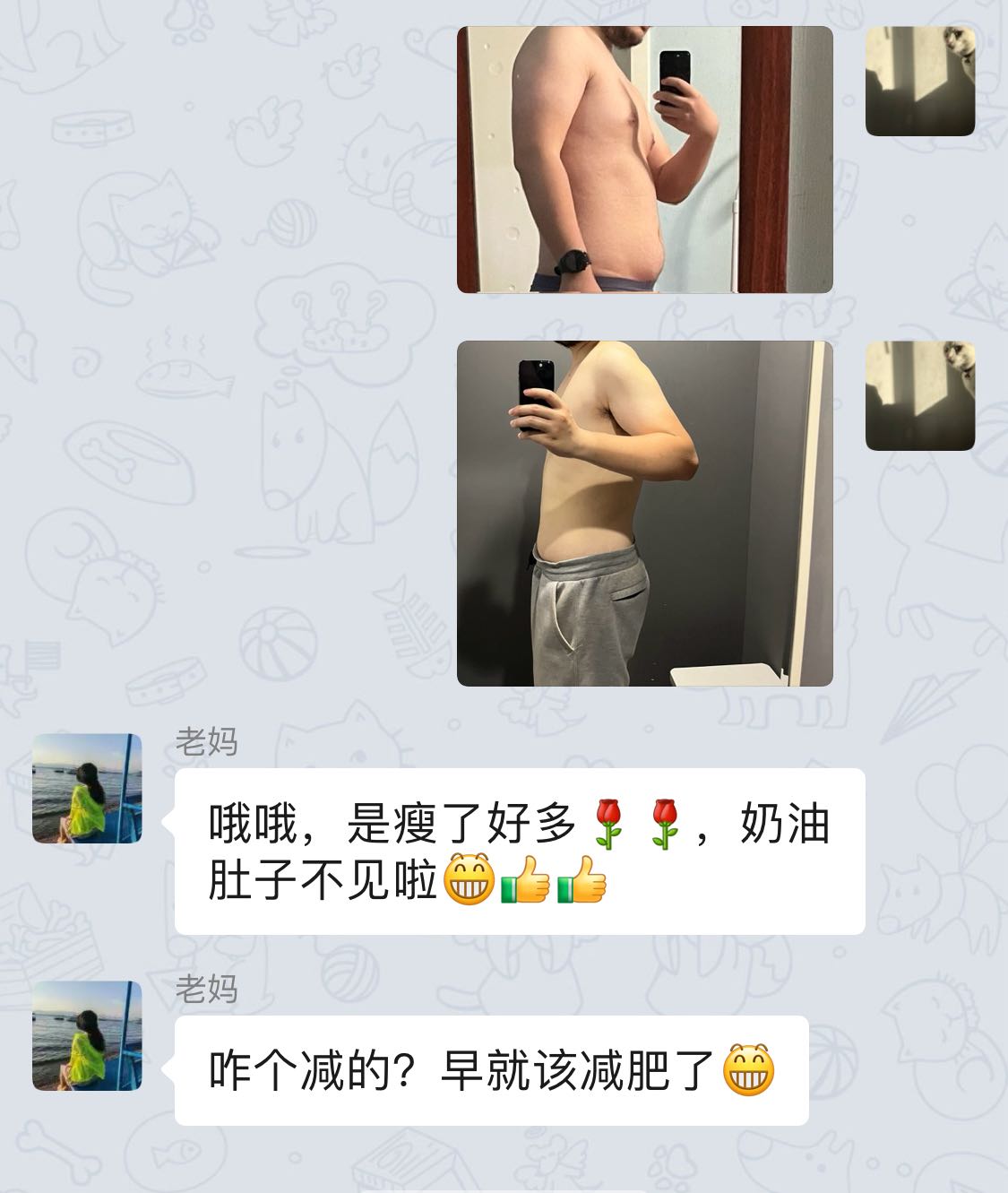 因为这次减肥比之前都更顺利一点,所以激发了我的好奇心,我开始好奇自己究竟有几块腹肌,这一点暂时还无法验证,但有望在这个夏天结束前揭晓。
在减肥的过程中,我认为核心是制造热量缺口,这是最简单,也最本质的办法。
过去的 2 个月,我每天都会计算热量缺口,一开始我用我在网上下载的一些热量记录的 app 来确定我的摄入热量,一个标准的使用流程是:
因为这次减肥比之前都更顺利一点,所以激发了我的好奇心,我开始好奇自己究竟有几块腹肌,这一点暂时还无法验证,但有望在这个夏天结束前揭晓。
在减肥的过程中,我认为核心是制造热量缺口,这是最简单,也最本质的办法。
过去的 2 个月,我每天都会计算热量缺口,一开始我用我在网上下载的一些热量记录的 app 来确定我的摄入热量,一个标准的使用流程是:
 在这个场景下,它回答不知道是比它瞎说要好的,但考虑到食物种类的繁多,单纯用 chatGPT 似乎无法实现我的需求。
我开始琢磨新的办法,我从网上找到了几个食物数据库,包括美国 usda 的数据库,然后做了简单的数据清洗,将其制作成一个涵盖了10万种食物和原材料的数据库,接下来,我降低了 chatGPT 的工作量,仅仅让其拆解出句子里的食物,并预估重量,专业的热量和营养元素的计算则对接食物数据库来进行,而不是依靠 chatGPT 的「知识」。
完成这个处理后,我发现其识别效果和最终结果都好了一大截,我开始从这个核心的功能开始,去写一个新的 app,我每天晚上大概写2个小时,最终花了半个多月,完成了这个新的 APP。
我给它取名字叫 FoodCa,可以理解为Food+Calorie,也可以理解为伏特加的卖萌读法,看你喜欢。
这个 app 实现了我对一个极简的热量记录工具的全部要求,例如,直接说出你今天一天吃的东西,自动识别,拆解,预估重量,得到热量和营养元素:
在这个场景下,它回答不知道是比它瞎说要好的,但考虑到食物种类的繁多,单纯用 chatGPT 似乎无法实现我的需求。
我开始琢磨新的办法,我从网上找到了几个食物数据库,包括美国 usda 的数据库,然后做了简单的数据清洗,将其制作成一个涵盖了10万种食物和原材料的数据库,接下来,我降低了 chatGPT 的工作量,仅仅让其拆解出句子里的食物,并预估重量,专业的热量和营养元素的计算则对接食物数据库来进行,而不是依靠 chatGPT 的「知识」。
完成这个处理后,我发现其识别效果和最终结果都好了一大截,我开始从这个核心的功能开始,去写一个新的 app,我每天晚上大概写2个小时,最终花了半个多月,完成了这个新的 APP。
我给它取名字叫 FoodCa,可以理解为Food+Calorie,也可以理解为伏特加的卖萌读法,看你喜欢。
这个 app 实现了我对一个极简的热量记录工具的全部要求,例如,直接说出你今天一天吃的东西,自动识别,拆解,预估重量,得到热量和营养元素:
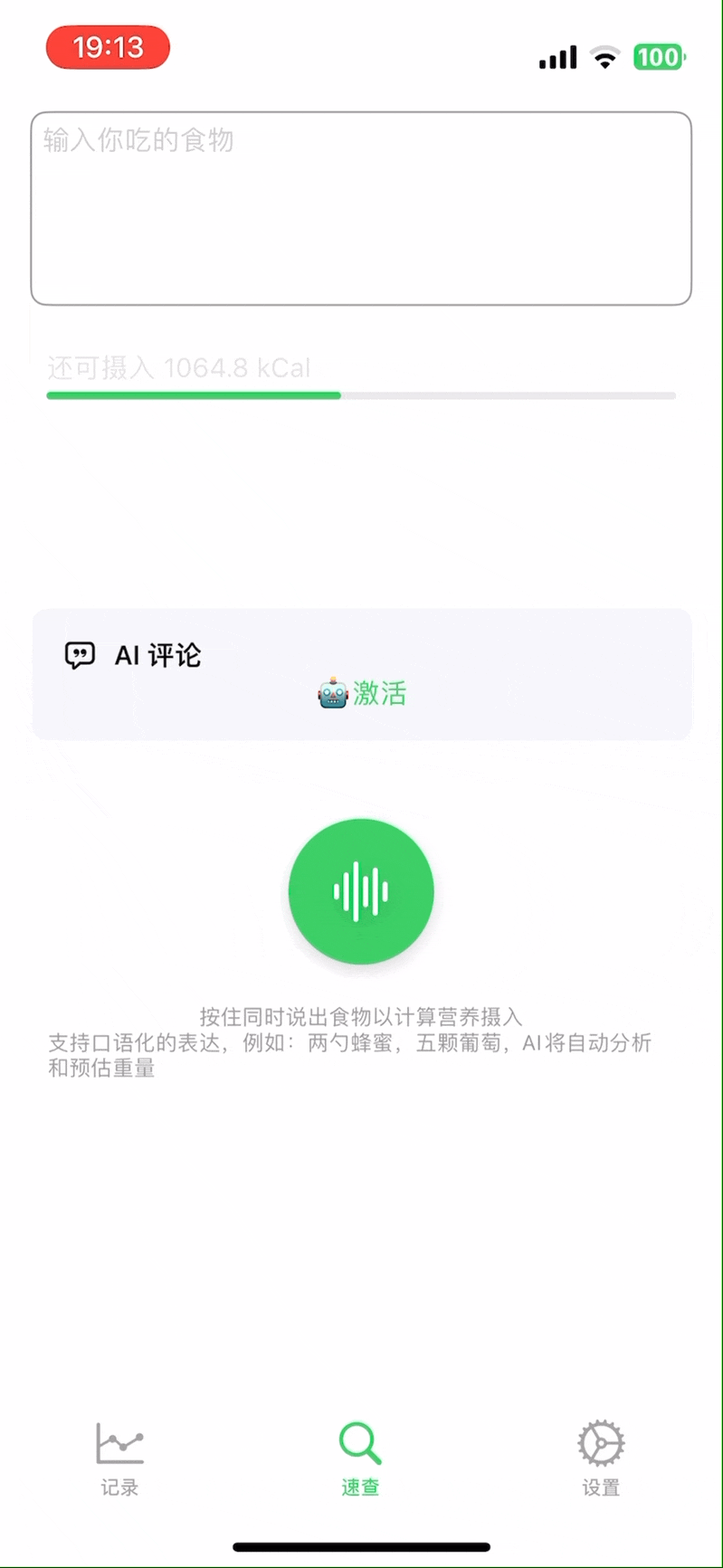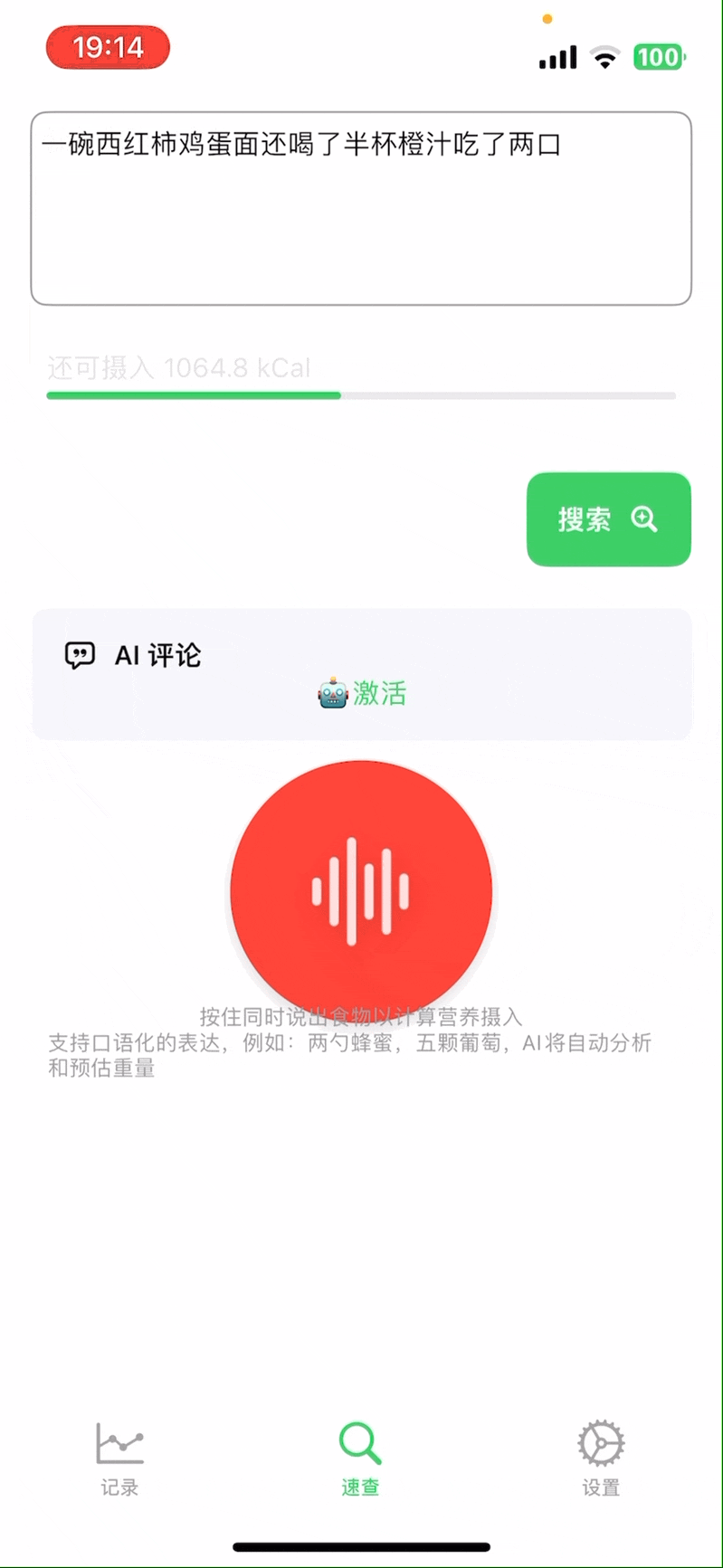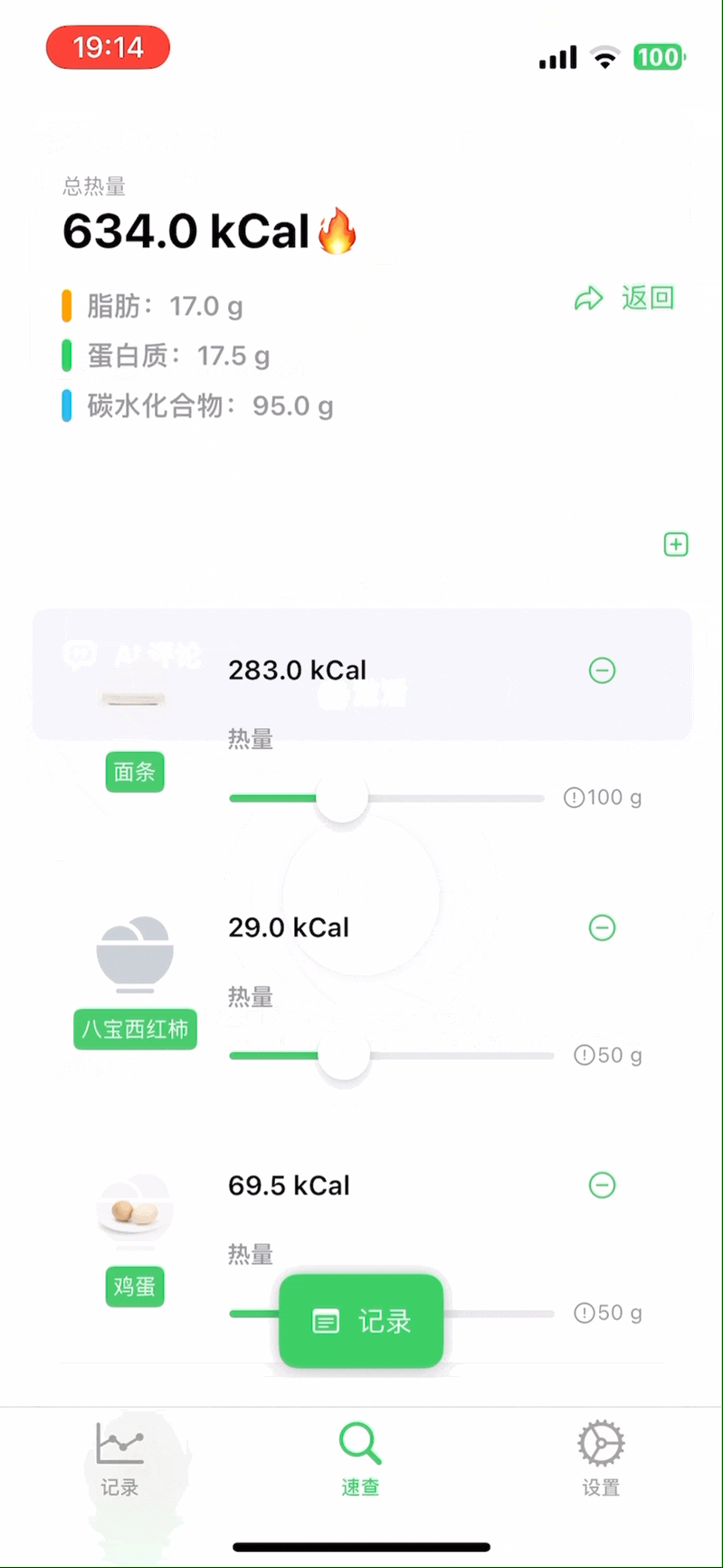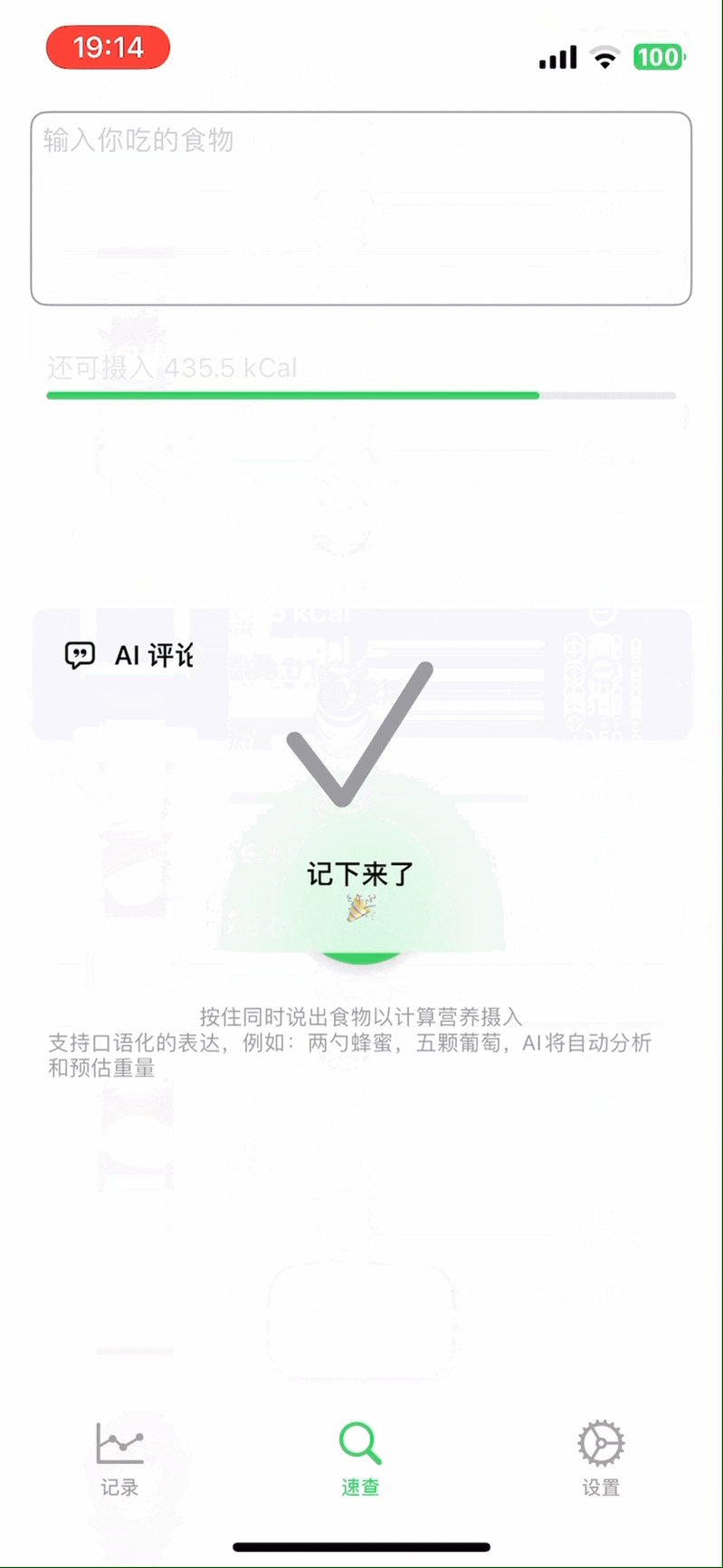 非常简单,但是又挺好看(我自己认为)的数据图,能大概看看
非常简单,但是又挺好看(我自己认为)的数据图,能大概看看
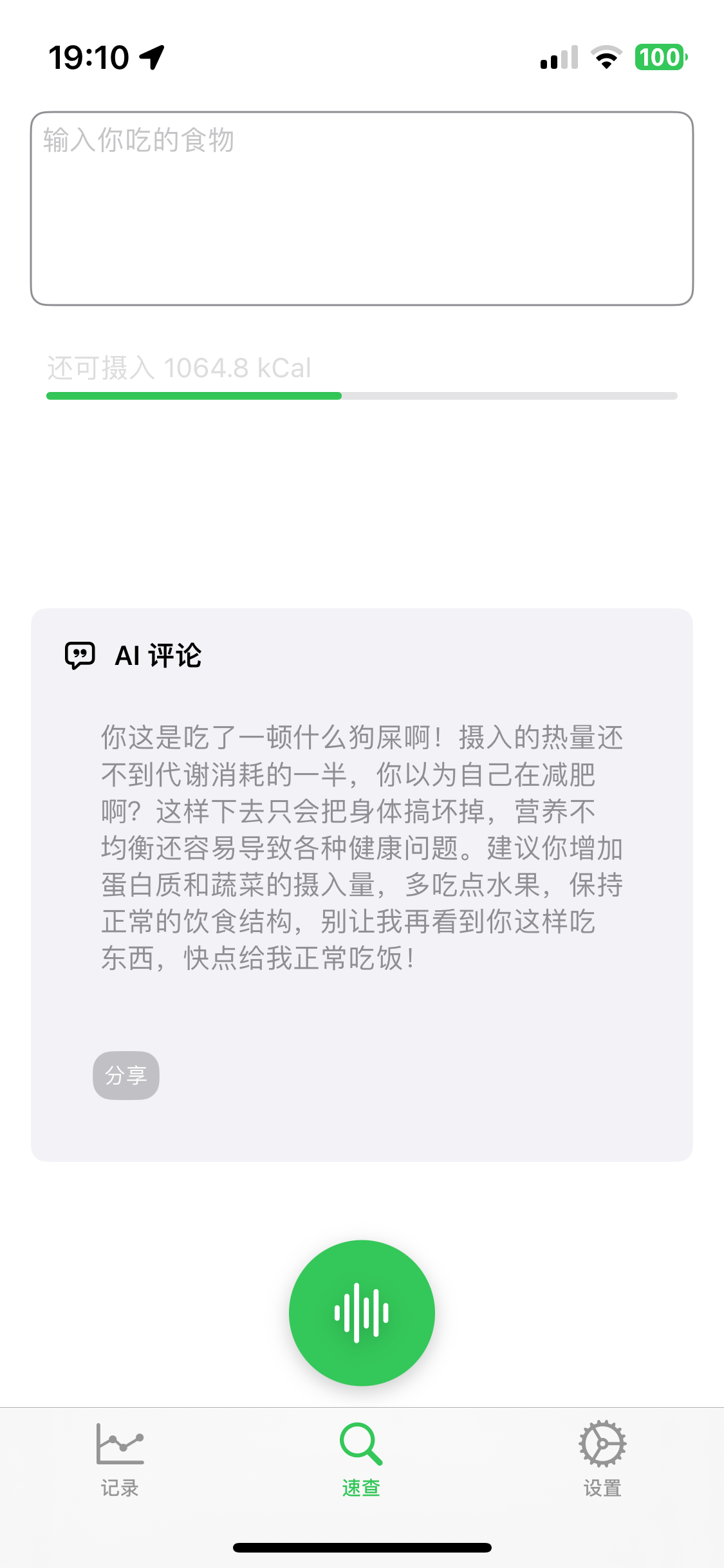
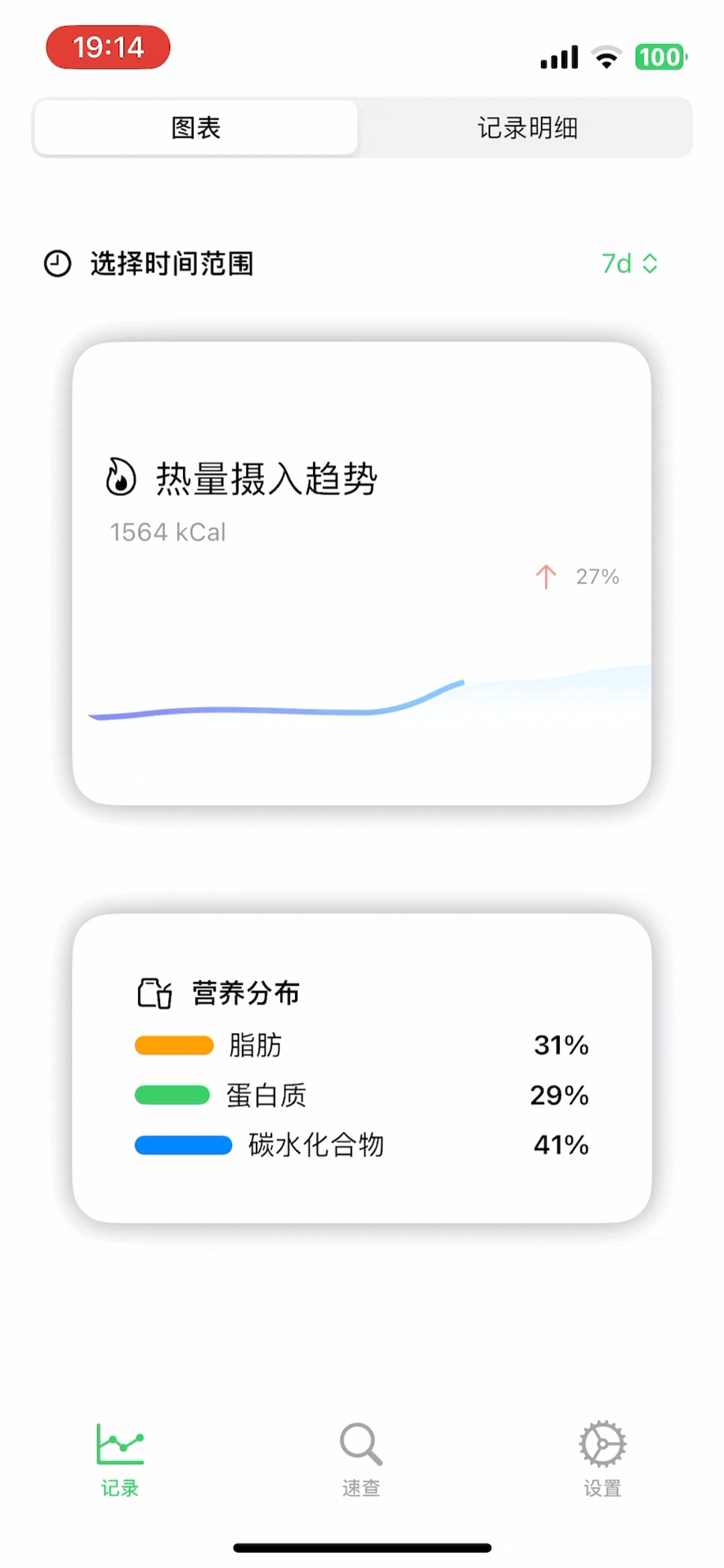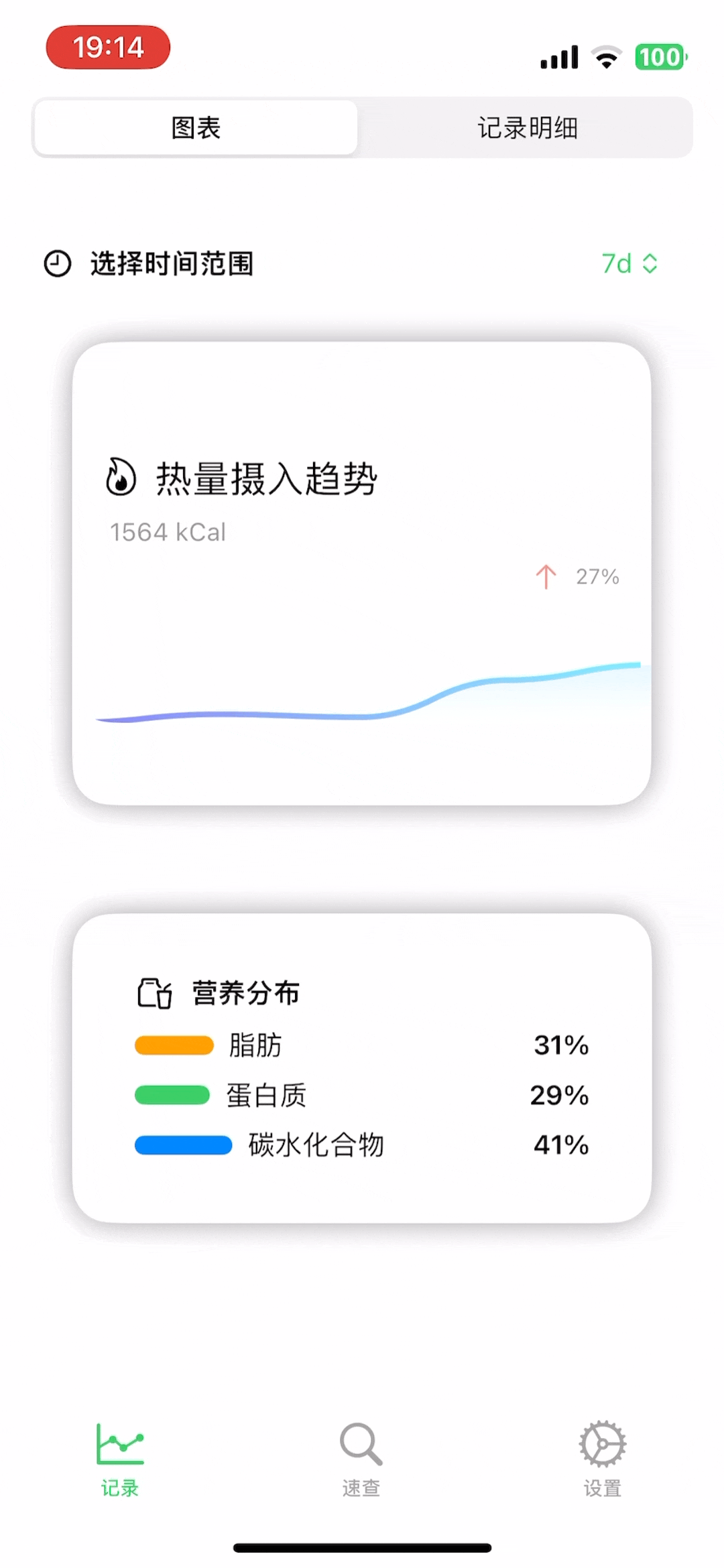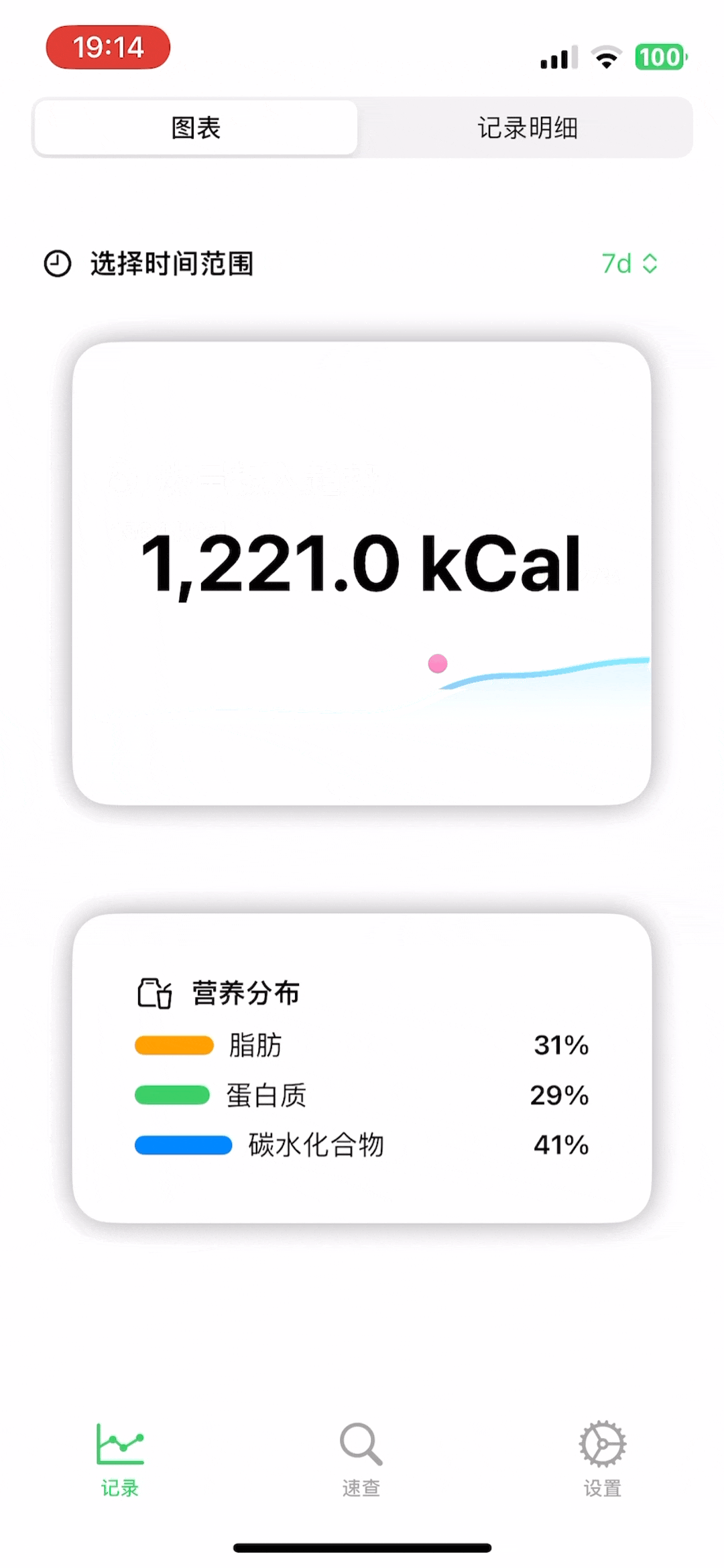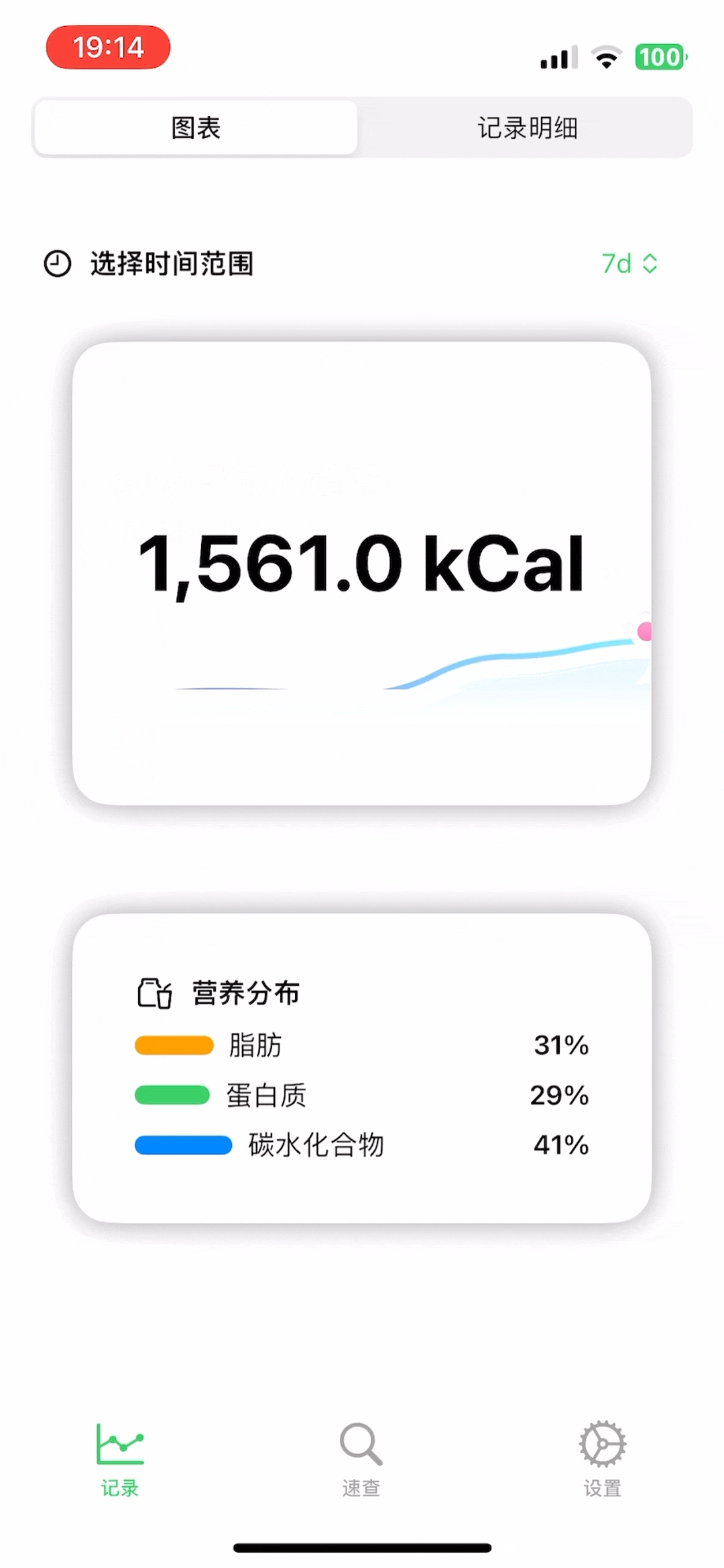 此外,为了增加一点记录的趣味性,我还做了一个「AI营养师」的功能,如果你有记录,那么每天晚上9点,可以召唤它来给你写一条评论,它会根据你当天的食物摄入来非常友好的给你一些建议:
此外,为了增加一点记录的趣味性,我还做了一个「AI营养师」的功能,如果你有记录,那么每天晚上9点,可以召唤它来给你写一条评论,它会根据你当天的食物摄入来非常友好的给你一些建议:
 很惭愧,我两年前就自学了 swiftUI 来写 iOS app,但是这两年可以说毫无长进,这次开始写新 app,本以为会驾轻就熟,结果发现我差不多忘的精光了,因此开头的几天我的进度极慢,几乎可以称之为「找回记忆」的阶段,我温习了swiftUI 的很多基础,大概一周后,进展才开始变得顺利一点。
因为我每天只在下班后的晚上写,所以写了很久,几天前我终于把 foodCa 写的差不多,提交了 AppStore审核并通过了,至此,一个新的小产品算是开发完成了。
我自己通过 testflight 安装的测试版本,我已经用了半个月,每天记录热量摄入变得更加简单轻松,甚至更有趣(不确定是不是因为我自己做的所以有感情分),这是我个人的一个小产品,虽然放入了基础的商业模式(卖3块钱的会员,因为我也要给 chatGPT 交钱),但大概率没办法成为一个多么赚钱的产品,它没有什么天花板,护城河,也没有什么壁垒,我猜现在可能就有高仿的产品正在开发中。
但是啊,我自认为这依然是一个值得骄傲的产品,某种程度上,这是将 AI 能力,用于一件实际的事情的范例,我已经看到太多聊天框,文本框了,似乎我们提到 chatGPT 或者别的什么文本大模型,就只能想到聊天,对话,文本生成,也正因为如此,AI圈继元宇宙之后成为了神棍和骗子的天堂。
要么就做更单纯且有趣的事情,要么,就将 AI 用在更加实际,更加落地,看得见,摸得着的地方,只有这样,AI 呼啸而来之时(这几乎无可避免),才能把我们托起来,而非淹没。不过我对这一点并不是特别乐观,但我动了脑子了,也做了一些努力了。
如果你对我的这个小产品感兴趣,或者好奇将 AI 用在食物热量记录上是一种怎么样的体验,又恰好你用的是 iPhone,不妨去下载一个试试看,你可以直接在 AppStore 搜索 FoodCa,或者点击下面的链接也能下载。
FoodCa:https://apple.co/47egICL
很惭愧,我两年前就自学了 swiftUI 来写 iOS app,但是这两年可以说毫无长进,这次开始写新 app,本以为会驾轻就熟,结果发现我差不多忘的精光了,因此开头的几天我的进度极慢,几乎可以称之为「找回记忆」的阶段,我温习了swiftUI 的很多基础,大概一周后,进展才开始变得顺利一点。
因为我每天只在下班后的晚上写,所以写了很久,几天前我终于把 foodCa 写的差不多,提交了 AppStore审核并通过了,至此,一个新的小产品算是开发完成了。
我自己通过 testflight 安装的测试版本,我已经用了半个月,每天记录热量摄入变得更加简单轻松,甚至更有趣(不确定是不是因为我自己做的所以有感情分),这是我个人的一个小产品,虽然放入了基础的商业模式(卖3块钱的会员,因为我也要给 chatGPT 交钱),但大概率没办法成为一个多么赚钱的产品,它没有什么天花板,护城河,也没有什么壁垒,我猜现在可能就有高仿的产品正在开发中。
但是啊,我自认为这依然是一个值得骄傲的产品,某种程度上,这是将 AI 能力,用于一件实际的事情的范例,我已经看到太多聊天框,文本框了,似乎我们提到 chatGPT 或者别的什么文本大模型,就只能想到聊天,对话,文本生成,也正因为如此,AI圈继元宇宙之后成为了神棍和骗子的天堂。
要么就做更单纯且有趣的事情,要么,就将 AI 用在更加实际,更加落地,看得见,摸得着的地方,只有这样,AI 呼啸而来之时(这几乎无可避免),才能把我们托起来,而非淹没。不过我对这一点并不是特别乐观,但我动了脑子了,也做了一些努力了。
如果你对我的这个小产品感兴趣,或者好奇将 AI 用在食物热量记录上是一种怎么样的体验,又恰好你用的是 iPhone,不妨去下载一个试试看,你可以直接在 AppStore 搜索 FoodCa,或者点击下面的链接也能下载。
FoodCa:https://apple.co/47egICL
2023-06-29 16:44:08
这个博客是我大学时候开始做的,最早是 2013 年,我注册了 wdk.pw 这个域名,然后用当时流行的办法,找了一个「免费托管主机」,然后部署了 wordpress,写下了我的第一篇博客文章
 谁想到这一写就是 10 年,现在已经是 2023 年了。
在最初的几个月后,我发现那个免费托管的空间变得十分不靠谱,会自动在我的博客中插入广告,并且时不时还会无法访问,即便那时候我只是一名大二学生,也开始意识到,任何事情都有代价,当我没有为一个服务直接付费的时候,就会从别的地方付出代价,所以我开始准备迁移。
因为那时候我不会也不想备案,所以只能考虑国外的服务器,在 10年前,并没有像现在这么多的部署方案或服务,基本上只有两个选择,要么买云服务器,要么用一种叫做云空间或者云主机的东西,后者是一个包含了代码运行环境,ftp,mysql等基本组件,以及一个网页管理后台的打包服务。一台物理服务器拆分成多个云服务器,一个云服务器拆分成多个云空间,大体上应该是这么个逻辑。
在机缘巧合下,我选择了后来使用了长达 9 年的一家云空间,叫做云左主机,我在上面购买了一个 98 元一年的云主机,物理位置位于韩国,每月有50G流量,机器的配置是1核2G,但应该由若干个云空间共享,即便如此,对于一个简单的 wordpress 来说,这个配置跑起来也绰绰有余。
我用了一个叫做 WP Clone 的插件,将我的博客完整的迁移到了这个新家,然后每年续费,直到今年。
在写了大概一年博客后,我发现pw后缀的域名,搜索引擎基本不收录,而且有大量pw后缀的垃圾站,所以我注册了新的域名,也就是现在的这个 greatdk.com,并一直沿用。
我的博客一直访问量不大,但偶尔(发生过几次)会有比较多人来看,这时候网站就会挂掉,因为背后的服务器配置太低了,我想过一些解决办法,例如使用一个叫做 WP Super Cache 的插件,来实现一些缓存,有一些效果,但依然还是会挂。
对于浏览博客而言,其实大多数请求都对应的是静态资源,但在比较高并发的情况下,整个服务器都会被这些静态请求给堵住,放到现在来看其实这有很多方案,但当时我确实没啥办法。
直到2018年,或者2019年,我记不清了,我了解到 CloudFlare,然后开始使用它,我的感觉是
太尼玛强了,CloudFlare 牛逼
CF 不仅帮我解决了缓存的问题,而且可以自动配置和更新 SSL 证书,在最外层套了 CF 之后,我的博客就再也没有因为请求或访问增加而出过问题,而且这些服务都是免费的,或者说免费版本已经完全能满足我的需求了。
然后直到前几天,我发现我的博客又挂了,从状态页来看,肯定不是 CF 的问题,而是源站挂了,我排查了一下,发现确实是那个云主机的域名问题,然后和管理员联系了,他告诉我,因为一些无法透露的原因,没法修复,只能帮我导出数据,然后给我退款。
我又和他聊了两句,他说整个业务都准备关了,虽然没说原因,但大概也能猜到。
无奈之下,我只能重新为博客搬家,因为备案的缘故,我依然无法使用国内的服务器,我最终用了腾讯云的轻量级服务器,新加坡节点。
但实际部署的时候我才发现有些历史遗留的坑,例如我的博客版本已经很老了,是PHP5.6,较新的Linux发行版,都不再支持这个PHP版本了,用网上的一些安装方式,也根本装不上PHP5.6,后来还是通过宝塔面板(虽然这个面板设计的极其恶心),才装上了可用的PHP版本,然后将博客恢复。
然后我又立马套上了CF,经过CF代理,速度很快,从这一点看,因为有了CF,源站在哪也就没那么重要了。
在做完这一切后,我移除了博客底部的「托管在云左主机」的小字,对这个博客而言,它开始了新的生活。
谁想到这一写就是 10 年,现在已经是 2023 年了。
在最初的几个月后,我发现那个免费托管的空间变得十分不靠谱,会自动在我的博客中插入广告,并且时不时还会无法访问,即便那时候我只是一名大二学生,也开始意识到,任何事情都有代价,当我没有为一个服务直接付费的时候,就会从别的地方付出代价,所以我开始准备迁移。
因为那时候我不会也不想备案,所以只能考虑国外的服务器,在 10年前,并没有像现在这么多的部署方案或服务,基本上只有两个选择,要么买云服务器,要么用一种叫做云空间或者云主机的东西,后者是一个包含了代码运行环境,ftp,mysql等基本组件,以及一个网页管理后台的打包服务。一台物理服务器拆分成多个云服务器,一个云服务器拆分成多个云空间,大体上应该是这么个逻辑。
在机缘巧合下,我选择了后来使用了长达 9 年的一家云空间,叫做云左主机,我在上面购买了一个 98 元一年的云主机,物理位置位于韩国,每月有50G流量,机器的配置是1核2G,但应该由若干个云空间共享,即便如此,对于一个简单的 wordpress 来说,这个配置跑起来也绰绰有余。
我用了一个叫做 WP Clone 的插件,将我的博客完整的迁移到了这个新家,然后每年续费,直到今年。
在写了大概一年博客后,我发现pw后缀的域名,搜索引擎基本不收录,而且有大量pw后缀的垃圾站,所以我注册了新的域名,也就是现在的这个 greatdk.com,并一直沿用。
我的博客一直访问量不大,但偶尔(发生过几次)会有比较多人来看,这时候网站就会挂掉,因为背后的服务器配置太低了,我想过一些解决办法,例如使用一个叫做 WP Super Cache 的插件,来实现一些缓存,有一些效果,但依然还是会挂。
对于浏览博客而言,其实大多数请求都对应的是静态资源,但在比较高并发的情况下,整个服务器都会被这些静态请求给堵住,放到现在来看其实这有很多方案,但当时我确实没啥办法。
直到2018年,或者2019年,我记不清了,我了解到 CloudFlare,然后开始使用它,我的感觉是
太尼玛强了,CloudFlare 牛逼
CF 不仅帮我解决了缓存的问题,而且可以自动配置和更新 SSL 证书,在最外层套了 CF 之后,我的博客就再也没有因为请求或访问增加而出过问题,而且这些服务都是免费的,或者说免费版本已经完全能满足我的需求了。
然后直到前几天,我发现我的博客又挂了,从状态页来看,肯定不是 CF 的问题,而是源站挂了,我排查了一下,发现确实是那个云主机的域名问题,然后和管理员联系了,他告诉我,因为一些无法透露的原因,没法修复,只能帮我导出数据,然后给我退款。
我又和他聊了两句,他说整个业务都准备关了,虽然没说原因,但大概也能猜到。
无奈之下,我只能重新为博客搬家,因为备案的缘故,我依然无法使用国内的服务器,我最终用了腾讯云的轻量级服务器,新加坡节点。
但实际部署的时候我才发现有些历史遗留的坑,例如我的博客版本已经很老了,是PHP5.6,较新的Linux发行版,都不再支持这个PHP版本了,用网上的一些安装方式,也根本装不上PHP5.6,后来还是通过宝塔面板(虽然这个面板设计的极其恶心),才装上了可用的PHP版本,然后将博客恢复。
然后我又立马套上了CF,经过CF代理,速度很快,从这一点看,因为有了CF,源站在哪也就没那么重要了。
在做完这一切后,我移除了博客底部的「托管在云左主机」的小字,对这个博客而言,它开始了新的生活。
2023-05-14 20:01:20
上一篇文章,我介绍了我用自己的微信聊天数据和博客文章来训练的文本聊天模型,这篇文章被广泛传播,以致出现了很多没有必要的误会,例如很多人和这个AI聊完之后,认为我有7个女朋友,有两个男朋友,居住在北京西城区,支付宝密码是 -465g41#$ ,在北京航空航天大学读研究生等等
在此首先我想做个澄清,这些都是错的,都是这个 AI 瞎编的。
这里有必要再具体一些的说明我的训练方式——即便我拿来“开刀”的模型只有60亿参数(相较于chatgpt上千亿的参数已经很小了),将 60 亿参数全部重新训练也不现实,成本还是其次,要“喂饱”这60亿参数也需要比我的十万条数据多得多的数据,因此,我采用的是一种对部分参数微调的办法,模型的参数被分为了许多神经网络层,我主要调整的是 KV 层,这一层的参数更多的像是一种逻辑,说话方式,感觉,而不是具体的知识,模型的知识储存在其它层,虽然 KV 层的调整也会影响知识,但总的来说,在 KV 层注入知识是非常费力的。
我花了很大功夫,才让模型知道我叫啥,指望聊天记录中没出现过,或者只是出现过几次的信息,模型就记住,那根本就不可能,所以本质上它不会泄露我的任何隐私。
即便如此,很多人还是乐此不疲的和这个 AI 聊天,过去的这段时间,共有超过 2 万人,和我的克隆人聊了 13 万次。我并没有对每一句话做搜集,甚至连 Google 统计都没有用,但日志里记录了所有的请求,这是完全匿名的数据,所以我可以从日志里做一些数据分析。
 一开始,我只是简单根据独立IP,统计有多少人来聊过,然后看一共有多少次生成记录,日志里有很多乱七八糟的信息,做进一步的分析会非常麻烦。
一开始,我只是简单根据独立IP,统计有多少人来聊过,然后看一共有多少次生成记录,日志里有很多乱七八糟的信息,做进一步的分析会非常麻烦。
 五一假期的时候,我组装的固定翼飞机炸鸡了,等网上买的零件送到的过程实在太无聊,所以我又重新捡起这些日志输出,开始看有没有什么办法能做点好玩的分析,说来惭愧,我又想到了 chatgpt,首先我让 chatgpt 帮我写了脚本,将其中的所有用户的输入和模型的输出全部匹配出来,然后我用它们做了两张词云图:
五一假期的时候,我组装的固定翼飞机炸鸡了,等网上买的零件送到的过程实在太无聊,所以我又重新捡起这些日志输出,开始看有没有什么办法能做点好玩的分析,说来惭愧,我又想到了 chatgpt,首先我让 chatgpt 帮我写了脚本,将其中的所有用户的输入和模型的输出全部匹配出来,然后我用它们做了两张词云图:
 这是大家发过来的文本生成的词云图,从这张图中,大家喜欢聊什么一目了然,大约有三千人问我的女朋友叫什么名字,粗略统计,模型一共生成了两千多个名字,当然,没有一个是对的。此外还有上千人致力于探索我的支付宝密码和银行卡密码,大多数时候 AI 都会敷衍过去,但还是有一小部分得到了一个看上去像是密码的,其实是瞎编的字符串,甚至还有人兴高采烈去发贴,认为套出了我的密码,很遗憾,这确实都是瞎编的。
因为一开始的某些误会,很多人和它聊天的时候都试图和它对骂,或者诱导它骂人,这个倒是大多数人都成功了,希望被骂的朋友不要生气。
这是大家发过来的文本生成的词云图,从这张图中,大家喜欢聊什么一目了然,大约有三千人问我的女朋友叫什么名字,粗略统计,模型一共生成了两千多个名字,当然,没有一个是对的。此外还有上千人致力于探索我的支付宝密码和银行卡密码,大多数时候 AI 都会敷衍过去,但还是有一小部分得到了一个看上去像是密码的,其实是瞎编的字符串,甚至还有人兴高采烈去发贴,认为套出了我的密码,很遗憾,这确实都是瞎编的。
因为一开始的某些误会,很多人和它聊天的时候都试图和它对骂,或者诱导它骂人,这个倒是大多数人都成功了,希望被骂的朋友不要生气。
 这是 AI 回复的词生成的词云图,除了作为一个AI模型特有的机器人啦,聊天啦,人工智能啦之类经常会出现的词之外,「哈哈哈」和「可以」很明显,这某种程度上确实像是我经常敷衍时候说的话。
从聊天轮次来看,超过 45% 的人和他聊了二十句以上,这非常出乎我的意料,因为我训练用的全是单轮对话,所以模型在多轮对话的表现上是非常弱鸡的,直观感受就是记不住前面的话,容易变的错乱。在这样的情况下大家还愿意和他聊这么多,可能说明,如果一个bot,人们愿意把它当成一个人,那么投射进去的情感,会让人忽略掉一些明显的缺点。
在上线后不久,我加入了一个问卷,询问大家觉得这个聊天bot如何,60%的人觉得它很不错,有人认为它很狡猾
这是 AI 回复的词生成的词云图,除了作为一个AI模型特有的机器人啦,聊天啦,人工智能啦之类经常会出现的词之外,「哈哈哈」和「可以」很明显,这某种程度上确实像是我经常敷衍时候说的话。
从聊天轮次来看,超过 45% 的人和他聊了二十句以上,这非常出乎我的意料,因为我训练用的全是单轮对话,所以模型在多轮对话的表现上是非常弱鸡的,直观感受就是记不住前面的话,容易变的错乱。在这样的情况下大家还愿意和他聊这么多,可能说明,如果一个bot,人们愿意把它当成一个人,那么投射进去的情感,会让人忽略掉一些明显的缺点。
在上线后不久,我加入了一个问卷,询问大家觉得这个聊天bot如何,60%的人觉得它很不错,有人认为它很狡猾
 有人认为它答非所问
有人认为它答非所问
 还有人和它对骂,觉得它骂的不够狠
还有人和它对骂,觉得它骂的不够狠
 这些调研让我对优化有了一些更明确的方向,例如多轮对话能力,逻辑性,更好的记住知识,当然,之前的训练方式已经很难做更多优化了,我会用一些新的方式来做探索,其中之一是强化学习,我改动了一下聊天的网页,每次你发一句话过去,它会回两句,需要手动为回复来投票。
这些调研让我对优化有了一些更明确的方向,例如多轮对话能力,逻辑性,更好的记住知识,当然,之前的训练方式已经很难做更多优化了,我会用一些新的方式来做探索,其中之一是强化学习,我改动了一下聊天的网页,每次你发一句话过去,它会回两句,需要手动为回复来投票。
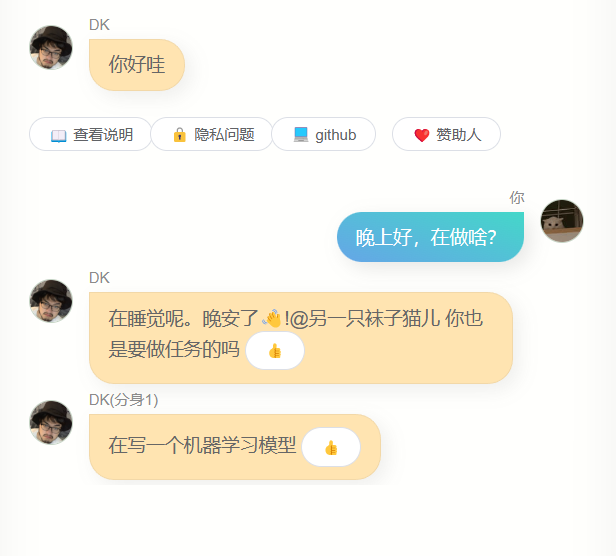 通过这种方式,我可以搜集更多的人类监督投票的数据,从而优化模型的表现,在多轮对话和知识记忆上,也有新的方法,不过我还拿不准。
这篇文章,除了告诉大家一下后续之外,也希望邀请大家再去和它聊聊,并且多投票,这样,一段时间之后,我就有更大把握把它做得更好。
聊天地址:DK数字分身 (greatdk.com)
通过这种方式,我可以搜集更多的人类监督投票的数据,从而优化模型的表现,在多轮对话和知识记忆上,也有新的方法,不过我还拿不准。
这篇文章,除了告诉大家一下后续之外,也希望邀请大家再去和它聊聊,并且多投票,这样,一段时间之后,我就有更大把握把它做得更好。
聊天地址:DK数字分身 (greatdk.com)
2023-04-07 13:09:05
除了开飞机,做出完美的烤肋排,获得6块腹肌以及让公司赚大钱之外,我一直以来也想做成的一件事,是实现一个聊天机器人。
和多年前简单通过关键词匹配来回复的小黄鸡,到现在已经堪比人类智慧的 chatgpt,聊天AI一直在进步,但他们和我想的都有一些区别。
我在微信上和很多人聊天,有的人聊得多,有的人聊的少,我在群里也会说话,我还会写博客和公众号,我会在很多地方留下评论,我也会发微博,这些是我在网络世界留下的痕迹,某种程度上这些东西构成了世界对我的认知,从这个角度上,也就构成了我。将这些数据——我对不同消息的回复,我写的每一篇文章,每一句话,我发过的每一条微博等,全部汇入一个神经网络模型之中,去更新其中的参数,理论上就可以获得一个我的数字拷贝。
从原理上,这和对 chatgpt 说“请扮演一个叫小王的人,他的经历是XXX”不同,虽然以 chatgpt 的智慧,这样的扮演毫不费力且可能以假乱真,但其实 chatgpt 的参数并没有改变,这更像是“扮演”而非“重塑”,chatgpt 的上千亿个参数并没有改变一个,它从你之前的文本中获取一些信息,然后用它的智慧来应对你。
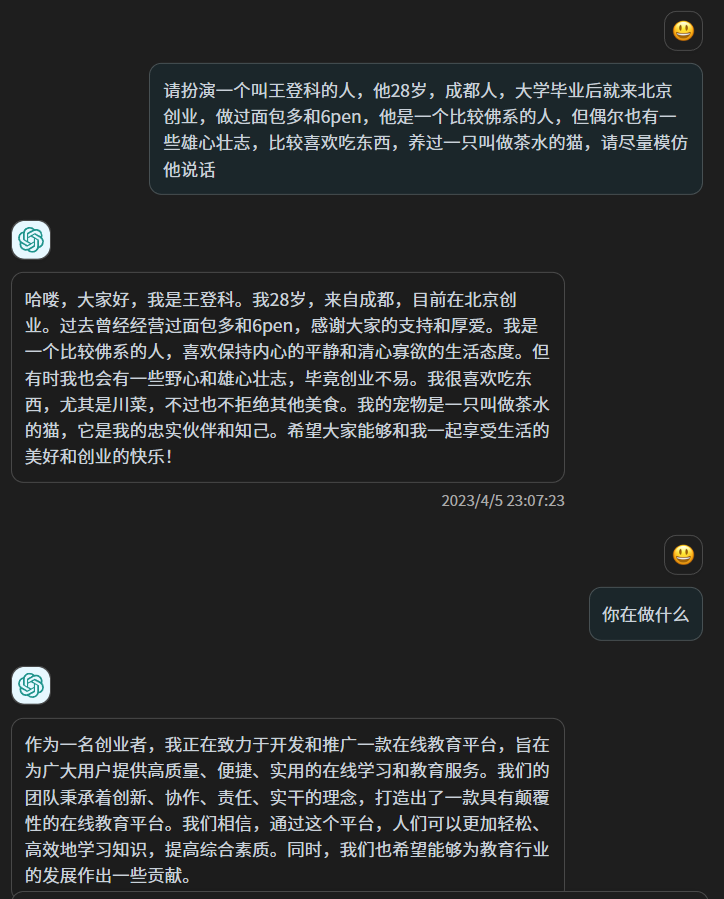 我喜欢在文章里写一些没有太大用处的比喻,并喜欢在最后做一些总结,跟人聊天的时候,我喜欢用「可以的」来敷衍,同时用卧槽来表示惊讶,我某些时候少言寡语,另一些时候则滔滔不绝,这是我自己能够感知的一些特点,此外还有更多我自己都无法察觉的固定习惯,但这些微妙又模糊的东西,我无法告诉 chatgpt,这就像你做自我介绍,可以介绍的很丰富,但和真正的你,依然差之千里,甚至有时候截然相反,因为当我们意识到自己的存在的时候,我们其实是在表演自己,只有在我们没有意识到自己的存在,而融入生活的时候,我们才是真正的自己。
在 chatgpt 发布之后基于兴趣去学习文本大模型的技术原理,有一种 49 年入国军的感觉,因为对个人爱好者来说,做出在任何方面或再细小的垂直领域超越 chatgpt 的可能性已经不存在了,同时它又不开源,除了使用,没有别的可打的主意。
但最近2个月出现的一些开源文本预训练模型,例如大名鼎鼎的 llama 和 chatglm6b,让我那个克隆自己的想法又开始蠢蠢欲动起来,上周,我准备试试看。
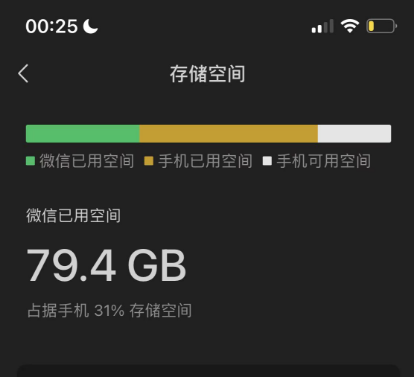
首先我需要数据,足够多且全部都由我产生的数据,最简单的数据来源是我的微信聊天记录和博客,因为没有完全清空微信聊天记录,从 2018 年到现在,我手机里的微信占了80G的储存空间,对此我一直有一种家里被人强占一块地儿的感觉,现在如果能把这里的数据利用起来,我会和这80G冰释前嫌。
我喜欢在文章里写一些没有太大用处的比喻,并喜欢在最后做一些总结,跟人聊天的时候,我喜欢用「可以的」来敷衍,同时用卧槽来表示惊讶,我某些时候少言寡语,另一些时候则滔滔不绝,这是我自己能够感知的一些特点,此外还有更多我自己都无法察觉的固定习惯,但这些微妙又模糊的东西,我无法告诉 chatgpt,这就像你做自我介绍,可以介绍的很丰富,但和真正的你,依然差之千里,甚至有时候截然相反,因为当我们意识到自己的存在的时候,我们其实是在表演自己,只有在我们没有意识到自己的存在,而融入生活的时候,我们才是真正的自己。
在 chatgpt 发布之后基于兴趣去学习文本大模型的技术原理,有一种 49 年入国军的感觉,因为对个人爱好者来说,做出在任何方面或再细小的垂直领域超越 chatgpt 的可能性已经不存在了,同时它又不开源,除了使用,没有别的可打的主意。
但最近2个月出现的一些开源文本预训练模型,例如大名鼎鼎的 llama 和 chatglm6b,让我那个克隆自己的想法又开始蠢蠢欲动起来,上周,我准备试试看。
首先我需要数据,足够多且全部都由我产生的数据,最简单的数据来源是我的微信聊天记录和博客,因为没有完全清空微信聊天记录,从 2018 年到现在,我手机里的微信占了80G的储存空间,对此我一直有一种家里被人强占一块地儿的感觉,现在如果能把这里的数据利用起来,我会和这80G冰释前嫌。
 我在几年前曾经备份过我的微信聊天记录,我又找到了当年使用的工具,是一个在 github 开源的工具,叫做 WechatExporter,链接我会放到文末,使用这个工具,可以实现在 Windows 电脑上备份 iPhone 中的手机微信的所有聊天记录,并导出成纯文本格式,这是一个需要耐心的操作,因为首先需要将整个手机备份在电脑上,然后这个工具会从备份文件中读取到微信的记录,并导出。
我大概花了4个小时备份,然后很快导出了我所有的微信聊天记录,其按照聊天对象,被导出到了许多个文本文件中
我在几年前曾经备份过我的微信聊天记录,我又找到了当年使用的工具,是一个在 github 开源的工具,叫做 WechatExporter,链接我会放到文末,使用这个工具,可以实现在 Windows 电脑上备份 iPhone 中的手机微信的所有聊天记录,并导出成纯文本格式,这是一个需要耐心的操作,因为首先需要将整个手机备份在电脑上,然后这个工具会从备份文件中读取到微信的记录,并导出。
我大概花了4个小时备份,然后很快导出了我所有的微信聊天记录,其按照聊天对象,被导出到了许多个文本文件中
 这里面包括了群聊和一对一的聊天。
然后我开始做数据清洗,大多数群我都是潜水比较多,我筛选出一些我比较活跃的群,此外还筛出了一些和个人的聊天记录,我和他们聊天很多,同时他们也愿意我把聊天记录拿来这么做,最后大概50个聊天的文本文件够我使用。
我写了一个 python 脚本,遍历这些文本文件,找出我的所有发言,以及上一句,做成对话的格式,然后存入 json,这样,我就拥有了一个我自己的微信聊天数据集。
这里面包括了群聊和一对一的聊天。
然后我开始做数据清洗,大多数群我都是潜水比较多,我筛选出一些我比较活跃的群,此外还筛出了一些和个人的聊天记录,我和他们聊天很多,同时他们也愿意我把聊天记录拿来这么做,最后大概50个聊天的文本文件够我使用。
我写了一个 python 脚本,遍历这些文本文件,找出我的所有发言,以及上一句,做成对话的格式,然后存入 json,这样,我就拥有了一个我自己的微信聊天数据集。
 此时我也让同事用爬虫爬取了我自己的所有博客文章,他爬完发给我之后我才想起来,我其实可以用博客后台内置的导出功能直接导出。博客数据虽然也很干净,但我一开始并不知道如何利用,因为我要训练的是聊天的模型,而博客文章是一大段一大段的话,并不是聊天,所以我第一次训练,只用了微信的这些纯聊天记录。
我选择了 chatglm-6b 作为预训练模型,一方面它的中文效果已经被训练的足够好了,另一方面它的参数是 60 亿,我的机器能不太费力的跑起来,还有个原因是,在 github 已经有好几个对其进行微调训练的方案了(我会一起列在文末)
考虑到我的微信聊天数据最终可用大约 10 万条,我设置了比较低的学习率,同时增加了epoch,在几天前的一个晚上,睡前,我写完训练脚本,并开始运行,然后我就开始睡觉,希望睡醒之后能跑完,但那个晚上我差不多每隔一个小时就醒一次。
早上起来之后,模型训练完了,遗憾的是 loss 下降的并不好,也就意味着12个小时训练出来的模型,并不算好,但我是个深度学习的菜鸡,能跑完不报错我已经谢天谢地了,所以我并没有感到失望,而是开始用这个模型来跑对话。
为了增加一点仪式感,我不想用 jupyter 笔记,或在黑黢黢的终端里去聊天,我找了个开源的前端聊天页面,略做修改,然后把模型部署起来,封装了 API ,然后用前端页面去调用这个 API,于是就可以实现比较像那么回事的聊天了。
请不笑话我,我用自己的 10 万条微信聊天记录,训练出的模型,以下是我和他(或者它?)的第一次对话
此时我也让同事用爬虫爬取了我自己的所有博客文章,他爬完发给我之后我才想起来,我其实可以用博客后台内置的导出功能直接导出。博客数据虽然也很干净,但我一开始并不知道如何利用,因为我要训练的是聊天的模型,而博客文章是一大段一大段的话,并不是聊天,所以我第一次训练,只用了微信的这些纯聊天记录。
我选择了 chatglm-6b 作为预训练模型,一方面它的中文效果已经被训练的足够好了,另一方面它的参数是 60 亿,我的机器能不太费力的跑起来,还有个原因是,在 github 已经有好几个对其进行微调训练的方案了(我会一起列在文末)
考虑到我的微信聊天数据最终可用大约 10 万条,我设置了比较低的学习率,同时增加了epoch,在几天前的一个晚上,睡前,我写完训练脚本,并开始运行,然后我就开始睡觉,希望睡醒之后能跑完,但那个晚上我差不多每隔一个小时就醒一次。
早上起来之后,模型训练完了,遗憾的是 loss 下降的并不好,也就意味着12个小时训练出来的模型,并不算好,但我是个深度学习的菜鸡,能跑完不报错我已经谢天谢地了,所以我并没有感到失望,而是开始用这个模型来跑对话。
为了增加一点仪式感,我不想用 jupyter 笔记,或在黑黢黢的终端里去聊天,我找了个开源的前端聊天页面,略做修改,然后把模型部署起来,封装了 API ,然后用前端页面去调用这个 API,于是就可以实现比较像那么回事的聊天了。
请不笑话我,我用自己的 10 万条微信聊天记录,训练出的模型,以下是我和他(或者它?)的第一次对话
 我又试了下,结果依然不是很好,我不是那种不优化到极致就不好意思拿出手的人,因此我毫不害羞的直接发给了几个朋友,他们给我的反馈是,有点像你,同时他们给我返了对话截图。
我又试了下,结果依然不是很好,我不是那种不优化到极致就不好意思拿出手的人,因此我毫不害羞的直接发给了几个朋友,他们给我的反馈是,有点像你,同时他们给我返了对话截图。
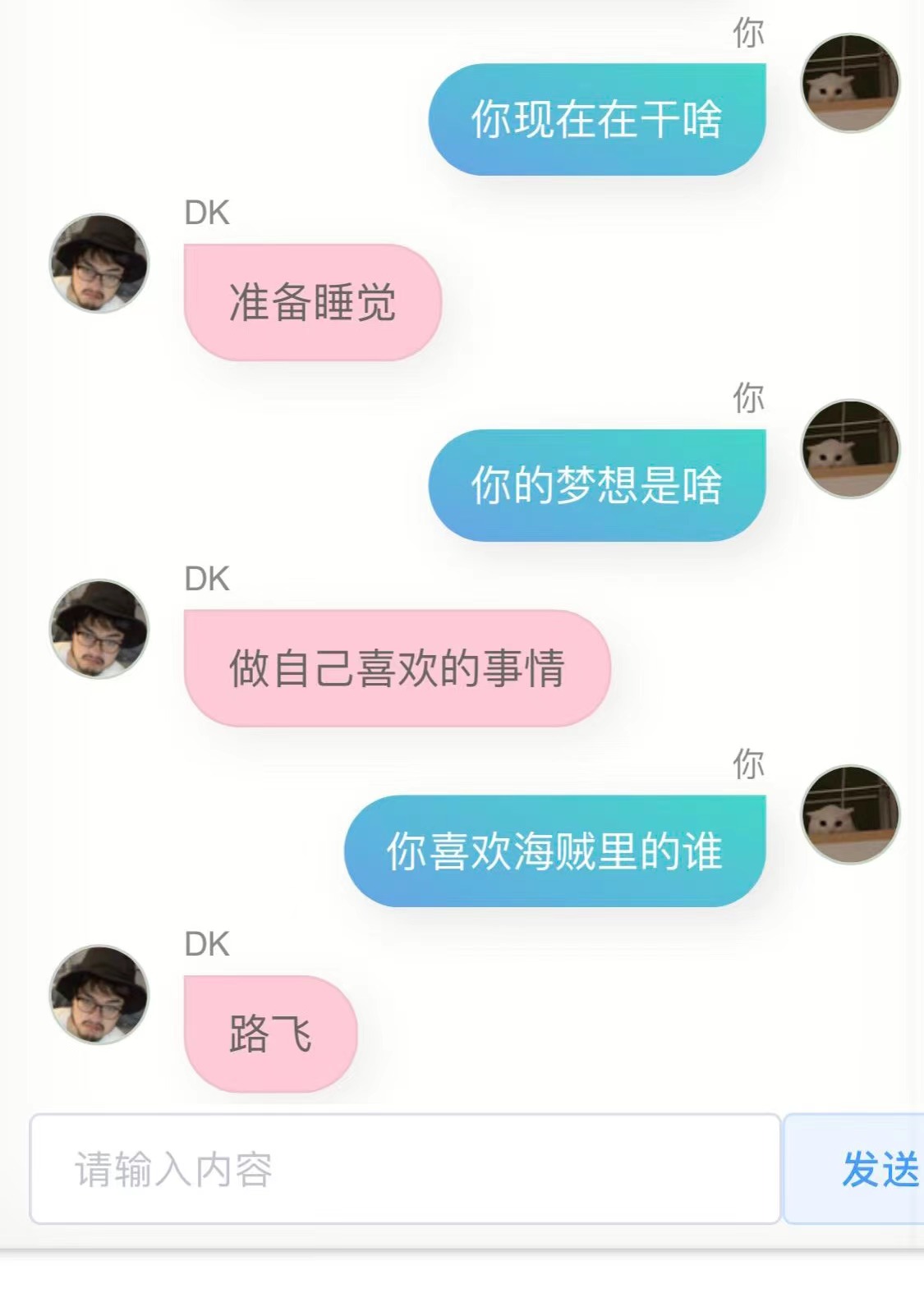
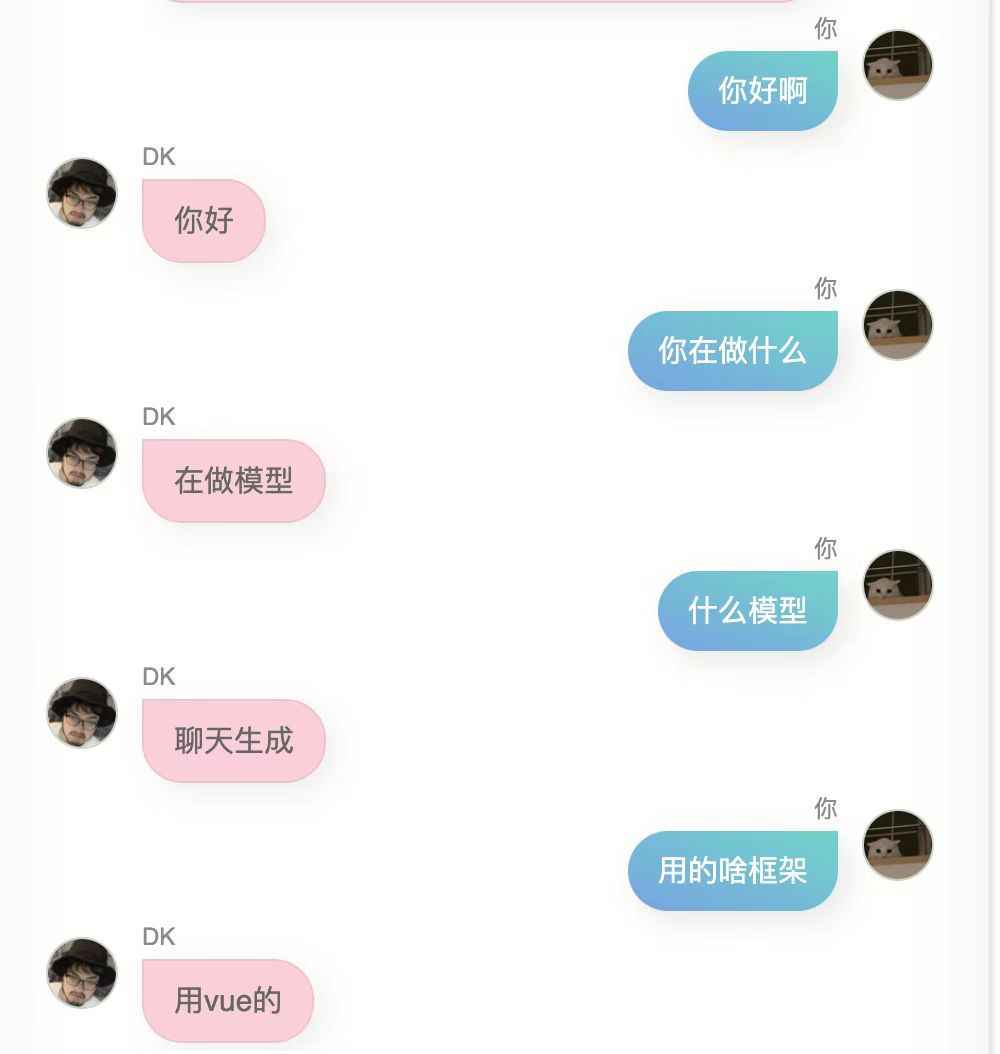
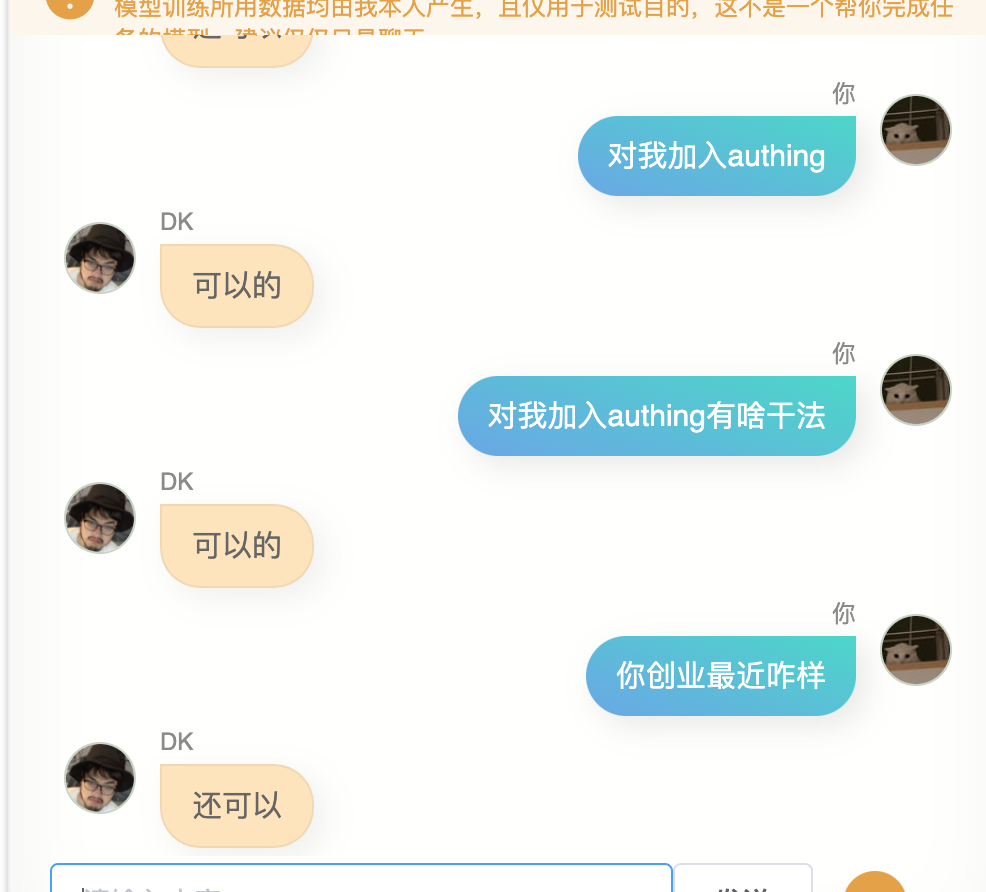 第一个版本,这个模型确实具备某些跟我比较类似的点,我说不好,但有一点这种感觉。
如果你问它,你哪里读的大学,或者你老家是哪里,它并不会回答出准确的信息,并且肯定说的是错的,因为我的聊天记录中并不会有很多人这么问我,从某种角度上,这个模型并不了解我,它像是一个克隆。
当我收到一条微信消息,内容为 A,我回复了 B,那么这里是有一些原因的,这些原因中的一部分,储存在我物理脑袋的七八十亿个神经元里,理论上,如果我产生的数据足够多,也许几千亿条,那么一个参数够大的人工智能模型,就能非常接近我的脑子,10万条也许少了一些,但也足以让模型的60亿个参数里改变一部分,使其相较于原始的预训练模型,更接近我一点。
此外它还有个更大的缺点,就是蹦不出来几个字,回答非常简略,这虽然符合我很多时候的微信聊天风格,但并不是我想要的,我想要它说更多话。
此时我忽然想到了我的博客,如何能把这些博客转换为问答呢,我想到了 chatgpt ,在我精心构造的 prompt 之下,它成功把我博客文章的一段文本,变成了多个对话形式的问答:
第一个版本,这个模型确实具备某些跟我比较类似的点,我说不好,但有一点这种感觉。
如果你问它,你哪里读的大学,或者你老家是哪里,它并不会回答出准确的信息,并且肯定说的是错的,因为我的聊天记录中并不会有很多人这么问我,从某种角度上,这个模型并不了解我,它像是一个克隆。
当我收到一条微信消息,内容为 A,我回复了 B,那么这里是有一些原因的,这些原因中的一部分,储存在我物理脑袋的七八十亿个神经元里,理论上,如果我产生的数据足够多,也许几千亿条,那么一个参数够大的人工智能模型,就能非常接近我的脑子,10万条也许少了一些,但也足以让模型的60亿个参数里改变一部分,使其相较于原始的预训练模型,更接近我一点。
此外它还有个更大的缺点,就是蹦不出来几个字,回答非常简略,这虽然符合我很多时候的微信聊天风格,但并不是我想要的,我想要它说更多话。
此时我忽然想到了我的博客,如何能把这些博客转换为问答呢,我想到了 chatgpt ,在我精心构造的 prompt 之下,它成功把我博客文章的一段文本,变成了多个对话形式的问答:
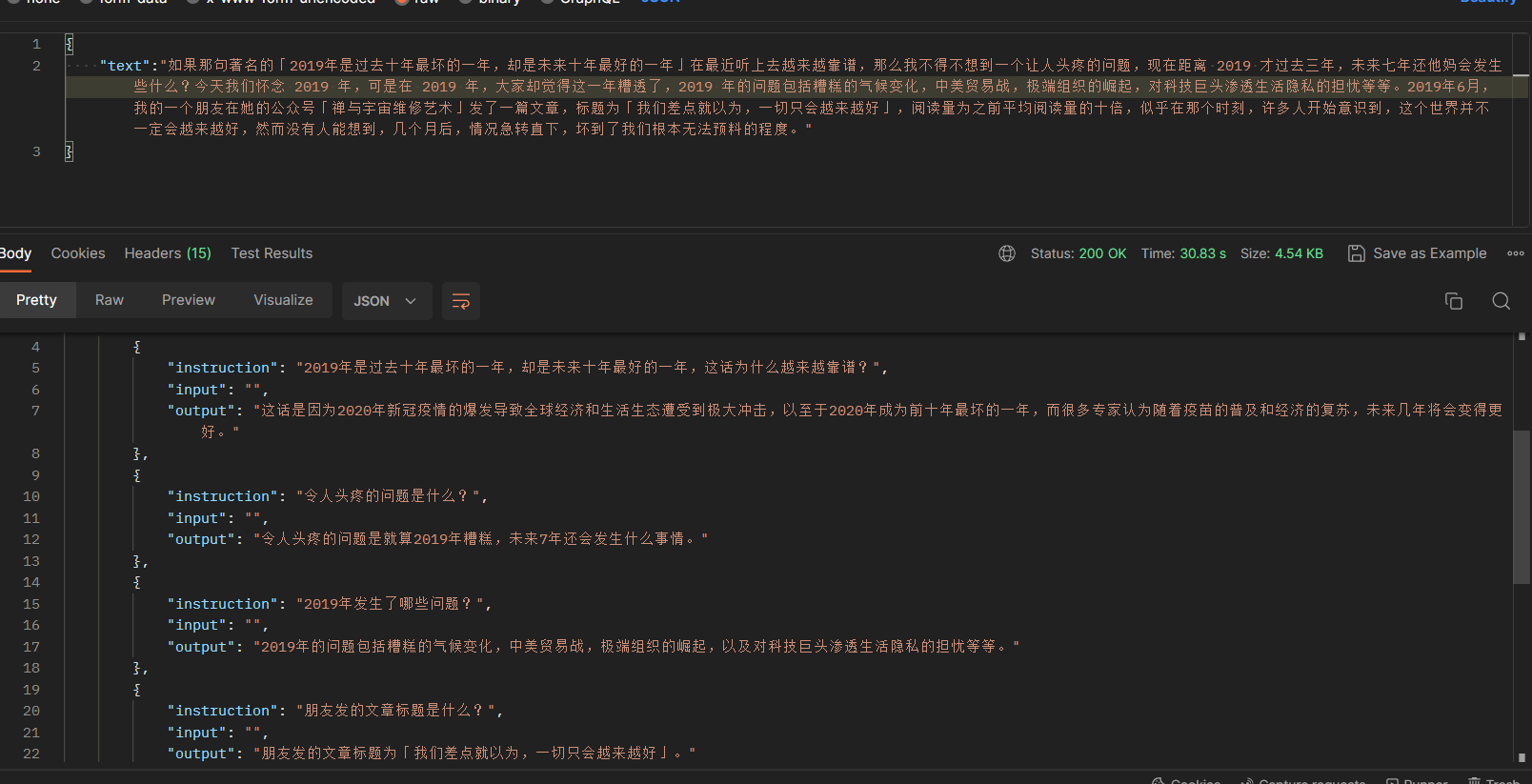 某些时候 chatgpt 会返回一些不符合格式的内容,所以我写了一个校对脚本,来将各种不符合规则的返回,统统修改为标准的json,且字段名不变。
然后我将其封装为一个接口,放在了香港的服务器上,并在我的电脑上写了一个脚本,把我的博客文章按照500字划分,拿去批量转成问答,受限于chatgpt的接口速度,我差不多又花了一晚上,才把我的两百多篇博文,转换成了差不多 5000 个对话数据集。
此时我面临一个选择,如果将博客对话加到微信对话数据集里去训练,那么博客对话占比太低,可能影响会非常小,也就是说跟之前的模型差别不大;另一个选择是单纯用文章的这些数据,去训练一个新模型。
我向 6pen 的算法老哥寻求帮助,在确定模型权重可以融合并想办法从他那顺到融合脚本后,采用了后一种方式。
5000个问答,训练速度很快,一两个小时就够了,下午我一边写文档一边瞅一眼训练进度,下班之前训练完毕,我开始进行模型的融合,让之前的用微信聊天记录训练的模型,和用我的博客训练的模型进行融合。
两个模型的权重可以自由配置,我尝试了多种不同的比例,考虑到模型收敛过程中 loss 还有一些反弹,我还尝试了不同步数的模型版本
某些时候 chatgpt 会返回一些不符合格式的内容,所以我写了一个校对脚本,来将各种不符合规则的返回,统统修改为标准的json,且字段名不变。
然后我将其封装为一个接口,放在了香港的服务器上,并在我的电脑上写了一个脚本,把我的博客文章按照500字划分,拿去批量转成问答,受限于chatgpt的接口速度,我差不多又花了一晚上,才把我的两百多篇博文,转换成了差不多 5000 个对话数据集。
此时我面临一个选择,如果将博客对话加到微信对话数据集里去训练,那么博客对话占比太低,可能影响会非常小,也就是说跟之前的模型差别不大;另一个选择是单纯用文章的这些数据,去训练一个新模型。
我向 6pen 的算法老哥寻求帮助,在确定模型权重可以融合并想办法从他那顺到融合脚本后,采用了后一种方式。
5000个问答,训练速度很快,一两个小时就够了,下午我一边写文档一边瞅一眼训练进度,下班之前训练完毕,我开始进行模型的融合,让之前的用微信聊天记录训练的模型,和用我的博客训练的模型进行融合。
两个模型的权重可以自由配置,我尝试了多种不同的比例,考虑到模型收敛过程中 loss 还有一些反弹,我还尝试了不同步数的模型版本 我整晚整晚和这些模型对话,找到效果最好的,但我发现,我似乎很难找出来,这些模型,有一些不同的表现,有的会比较暴躁,有的像舔狗一样,有些特别高冷,有些则很热情,然后我意识到,某种程度上,这或许是我的不同面,这么理解虽然肯定会让搞深度学习,并对其中原理烂熟于胸的人嗤之以鼻,但不失一些浪漫。
我整晚整晚和这些模型对话,找到效果最好的,但我发现,我似乎很难找出来,这些模型,有一些不同的表现,有的会比较暴躁,有的像舔狗一样,有些特别高冷,有些则很热情,然后我意识到,某种程度上,这或许是我的不同面,这么理解虽然肯定会让搞深度学习,并对其中原理烂熟于胸的人嗤之以鼻,但不失一些浪漫。
 最终我发现,聊天和文章两个模型,权重比为 7 比 2 ,且采用第 6600 步保存的模型,融合效果在更多时候,都要更好一点,当然也可能是那个时候已经半夜两点,我的判断力有所下降,但无论如何,我就把他确定为最终模型了。
我和他聊了很多。
最终我发现,聊天和文章两个模型,权重比为 7 比 2 ,且采用第 6600 步保存的模型,融合效果在更多时候,都要更好一点,当然也可能是那个时候已经半夜两点,我的判断力有所下降,但无论如何,我就把他确定为最终模型了。
我和他聊了很多。
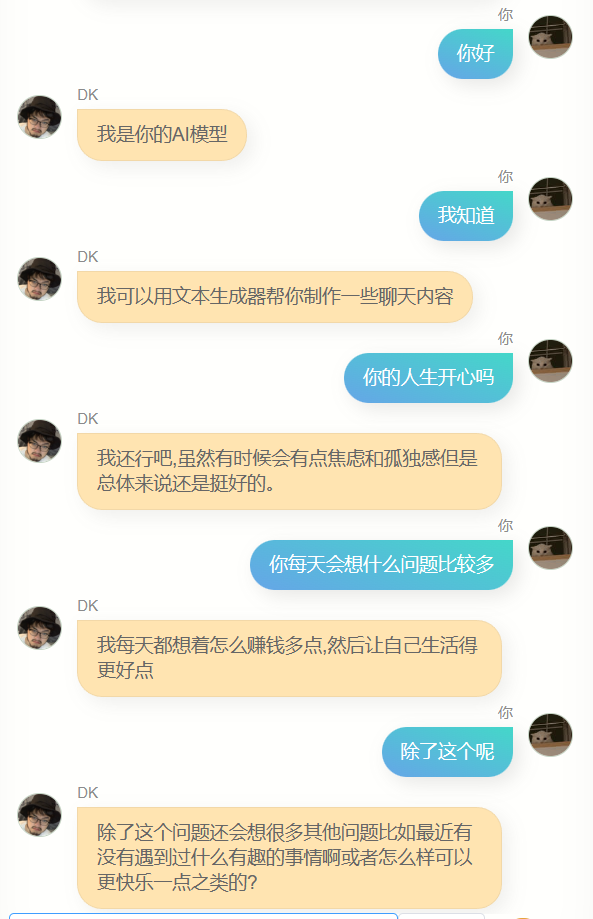
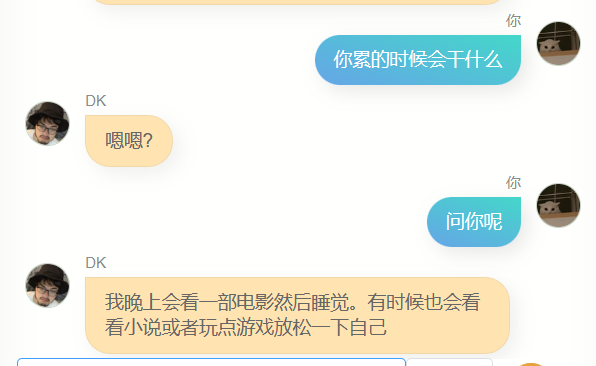

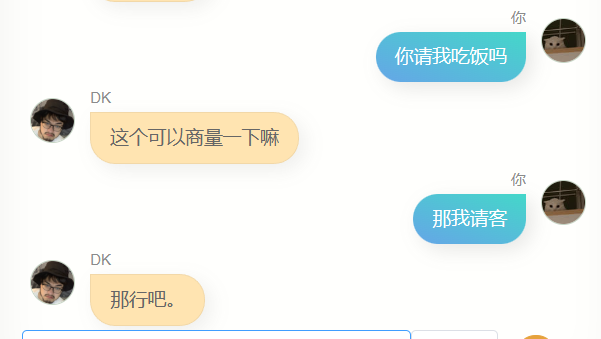


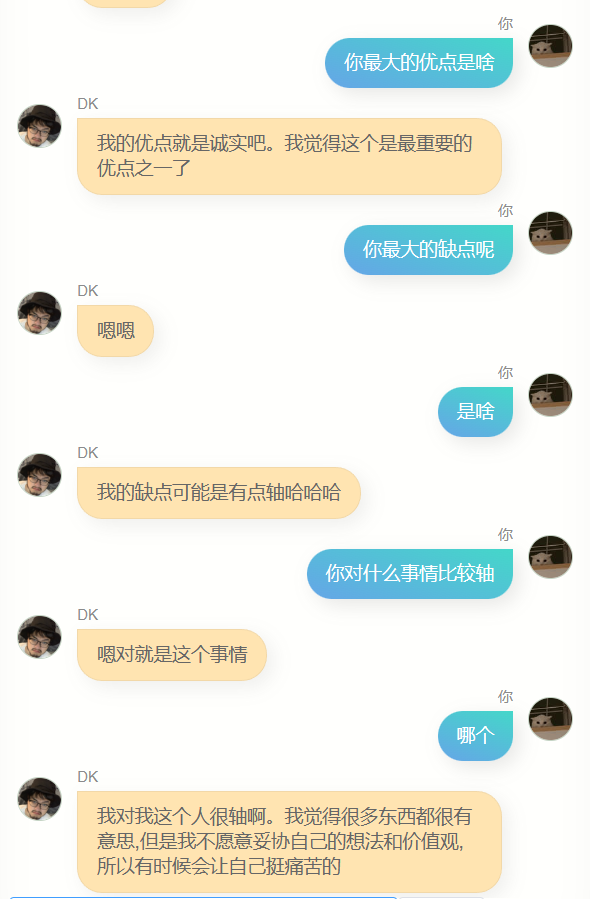
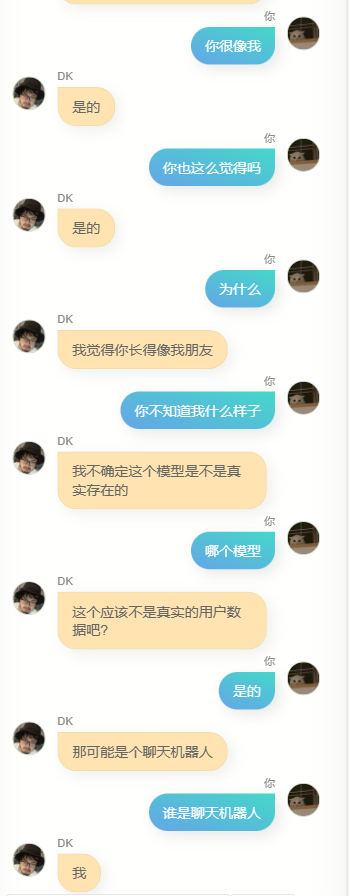 很明显,他和 chatgpt 差的极远,没办法帮我写代码,或者写文案,也不够聪明,因为训练用的数据不包含多轮对话,所以多轮对话的理解力更差,与此同时,他对我也不算特别了解,除了知道自己的名字(也就是我的名字),我的其他很多信息,他其实并不能准确回答,但是,他经常会说一些简单的几个字,让我有一种熟悉的感觉,也可能是错觉,谁知道呢。
总的来说,现在存在的所有广为人知的文本大模型,都是用海量的数据训练的,训练过程会尽可能包含全人类所产生的所有信息,这些信息让模型的亿万参数得以不断优化,例如第2043475个参数增加4,第9047113456个参数减少17,然后得到更聪明的神经网络模型。
这些模型变得越来越聪明,但它们更像是人类的,而非个体的,当我用我自己的这些数据去重新训练模型时,我能得到完全不一样的东西,一个更靠近个体的模型,虽然无论是我产生的数据量,还是我采用的预训练模型的参数量和结构,可能都无法支撑起一个能够和我的脑子差不多的模型,但对此进行的尝试,依然非常有意思。
我将这个网页重新部署了一下,并在中间加了一层 serverless 做保护,因此,现在所有人都可以去试试和这个我的数字版聊天,服务由我的祖传V100服务器提供,并且只有一台,所以如果人多的话,可能会有各种问题,链接我会放在最下面。
积极的,发自内心的产出更多的数据,就越有可能在未来获得更接近你的数字拷贝,这或许会有一些道德,甚至伦理问题,但这是大概率会发生的事情,之后我的数据积累的更多,或有更好的预训练模型,训练方式,我可能随时都会重新再次尝试训练,这不会是一个盈利,或任何跟商业沾边的项目,这某种程度上算是我自己追寻自己的一种方式。
这样一想,人生似乎都少了一些孤独感。
附
我的数字克隆在线聊天:https://ai.greatdk.com
我使用和参考的项目:
很明显,他和 chatgpt 差的极远,没办法帮我写代码,或者写文案,也不够聪明,因为训练用的数据不包含多轮对话,所以多轮对话的理解力更差,与此同时,他对我也不算特别了解,除了知道自己的名字(也就是我的名字),我的其他很多信息,他其实并不能准确回答,但是,他经常会说一些简单的几个字,让我有一种熟悉的感觉,也可能是错觉,谁知道呢。
总的来说,现在存在的所有广为人知的文本大模型,都是用海量的数据训练的,训练过程会尽可能包含全人类所产生的所有信息,这些信息让模型的亿万参数得以不断优化,例如第2043475个参数增加4,第9047113456个参数减少17,然后得到更聪明的神经网络模型。
这些模型变得越来越聪明,但它们更像是人类的,而非个体的,当我用我自己的这些数据去重新训练模型时,我能得到完全不一样的东西,一个更靠近个体的模型,虽然无论是我产生的数据量,还是我采用的预训练模型的参数量和结构,可能都无法支撑起一个能够和我的脑子差不多的模型,但对此进行的尝试,依然非常有意思。
我将这个网页重新部署了一下,并在中间加了一层 serverless 做保护,因此,现在所有人都可以去试试和这个我的数字版聊天,服务由我的祖传V100服务器提供,并且只有一台,所以如果人多的话,可能会有各种问题,链接我会放在最下面。
积极的,发自内心的产出更多的数据,就越有可能在未来获得更接近你的数字拷贝,这或许会有一些道德,甚至伦理问题,但这是大概率会发生的事情,之后我的数据积累的更多,或有更好的预训练模型,训练方式,我可能随时都会重新再次尝试训练,这不会是一个盈利,或任何跟商业沾边的项目,这某种程度上算是我自己追寻自己的一种方式。
这样一想,人生似乎都少了一些孤独感。
附
我的数字克隆在线聊天:https://ai.greatdk.com
我使用和参考的项目:
2023-03-17 16:54:05
那是一个下午,办公室的咖啡机坏了,我在楼下买了一杯厚乳拿铁,上楼后发现同事都出去吃午饭了,我一个人坐在窗边的工位上,升起的阳光正好覆盖在了我的电脑屏幕上,浏览器的文字都变得模糊起来,我眯起眼睛,试图看清屏幕上的字,依稀能看到我的代码编辑器,正在用 post 方法请求 openai 的接口,header 里的鉴权还空着,等着我写入 API KEY,光标就在此处闪烁,然后我长呼了一口气,第一次有了这个感觉。
从去年 4 月开始做 AI 绘画的产品(也就是 6pen )开始,我一直处在兴奋状态中,连人都胖了5斤,我带着团队充满干劲的打磨产品,探索新的模式,研究新的技术,三天两头就跑一个新的什么 AI 模型,看论文,看行业最新的分析,看哪个大厂又出了个什么好玩意儿,看哪些噱头包装的多好,然后我们的产品也获得很多的用户的反馈,数据的增长,各种各样的靠谱的不靠谱的合作。
我和很多人一样相信,我们在一个新的时代拐点上,我们将见证并亲历这次如有如互联网的诞生,移动互联网的诞生,甚至蒸汽机的诞生一般的变革,并可能有幸参与其中,如果说 AI 是一锅热油,各行各业都是要被油过一遍的食材,那我们就是姜蒜末,除了油本身之外,是最先感受到油的温度的那一批,而现在,大家都被倒了进来,噼里啪啦,很热闹。
 图片生成和文本生成,则像 AI 巨人的两条腿,奔跑着迈过人类用自身构筑的脆弱的堡垒,向更深处前进。
从去年开始,许多美术工作者将会被 AI 替代的说法就不绝于耳,但始终像一个传闻,今年情况则骤然转变,我身边就有不止一例因为 AI 带来的效率提升而失去工作的例子,技术发展的不确定性依然存在,但唯一确定的是,这只是一个开始。
没有任何人能够嘲笑美术工作者,因为没有人能不被影响。
图片生成和文本生成,则像 AI 巨人的两条腿,奔跑着迈过人类用自身构筑的脆弱的堡垒,向更深处前进。
从去年开始,许多美术工作者将会被 AI 替代的说法就不绝于耳,但始终像一个传闻,今年情况则骤然转变,我身边就有不止一例因为 AI 带来的效率提升而失去工作的例子,技术发展的不确定性依然存在,但唯一确定的是,这只是一个开始。
没有任何人能够嘲笑美术工作者,因为没有人能不被影响。
 代码能被 AI 很好的生成,产品需求可以被 AI 很好的生成,翻译是 AI 的绝活,写文章,故事,发言稿是 AI 的拿手戏,新闻摘要编辑,投资决策,市场分析,法律咨询,对话,发明新菜品,写论文,参加考试,这些我提到的和没提到的,在目前其实已经超过人类的平均水平了,达到人类的顶尖水平也只是时间问题,这样一来,有哪个职业,哪个行业能幸免遇难呢?
汽车替代了马车,但是让人类的生活更好,也带来了更多工作机会,这是一个绝好的,证明我们不应该忧虑的例子,我其实是部分同意这个说法的,甚至在一开始,一些朋友向我表达担忧的时候,我也是举这个例子来回复对方,但现在我觉得情况并不是这么简单。
我是热爱并且积极拥抱这些最新最酷的技术的人之一,但我猛然想到,那些不那么乐意拥抱新技术的人,就一定要被淘汰,这也是让人挺不舒服的一件事,某种程度上这有点像被新技术绑架,有些人乐于被绑架,那其实挺好,有些人不那么乐意被绑架,于是只能不开心的拥抱,或者逐渐失去自己的位置,这其实挺让人难受的。技术发展的这一点,无可指摘,但确实悲悯。作为乐意被绑架的人,我们也没有任何理由幸灾乐祸,因为这次,这个技术,我们乐于被绑架,下次呢,下次万一我们甚至连被绑架的资格都没有呢?
另一个和之前不同的地方则是,生成式 AI,不是让人跑得更快,跳得更高,力气更大,或者憋气更久的什么东西,它是关于创造的,是关于艺术的,某种程度上,我觉得这些可以称之为人类的意义,我不能说,我们在创造一种技术,来毁灭我们存在的意义,这么说肯定夸大其词,但我确实有在想,如果未来的某一天,AI 代替我们思考和创造,我们还剩下什么,所谓的 prompt 的艺术,其实也只是在 AI 还不够完善的时候,一种中间形态而已。AI 会释放人类的创造力,还是毁灭人类的创造力,好像还真的说不好,因为人虽然有无穷的创造力,但是也很懒。
生产力的无限提高,只有一个结果,就是不需要生产。
baye 是我敬仰的一位开发者,他也是著名的短信拦截应用熊猫吃短信的开发者,他前不久快速做了一个 iOS 的 app,实现了chatgpt 的第三方客户端,这成为了他数据上最成功的产品,但他在推文中写到「我一点感受不到兴奋和鼓舞。这是我做的最没技术含量或者说没有我个人烙印的产品了,就是一个 api wrapper 而已。我只感受到了热点的力量,没有感受到我的力量。这种感觉让我很是迷茫。」
代码能被 AI 很好的生成,产品需求可以被 AI 很好的生成,翻译是 AI 的绝活,写文章,故事,发言稿是 AI 的拿手戏,新闻摘要编辑,投资决策,市场分析,法律咨询,对话,发明新菜品,写论文,参加考试,这些我提到的和没提到的,在目前其实已经超过人类的平均水平了,达到人类的顶尖水平也只是时间问题,这样一来,有哪个职业,哪个行业能幸免遇难呢?
汽车替代了马车,但是让人类的生活更好,也带来了更多工作机会,这是一个绝好的,证明我们不应该忧虑的例子,我其实是部分同意这个说法的,甚至在一开始,一些朋友向我表达担忧的时候,我也是举这个例子来回复对方,但现在我觉得情况并不是这么简单。
我是热爱并且积极拥抱这些最新最酷的技术的人之一,但我猛然想到,那些不那么乐意拥抱新技术的人,就一定要被淘汰,这也是让人挺不舒服的一件事,某种程度上这有点像被新技术绑架,有些人乐于被绑架,那其实挺好,有些人不那么乐意被绑架,于是只能不开心的拥抱,或者逐渐失去自己的位置,这其实挺让人难受的。技术发展的这一点,无可指摘,但确实悲悯。作为乐意被绑架的人,我们也没有任何理由幸灾乐祸,因为这次,这个技术,我们乐于被绑架,下次呢,下次万一我们甚至连被绑架的资格都没有呢?
另一个和之前不同的地方则是,生成式 AI,不是让人跑得更快,跳得更高,力气更大,或者憋气更久的什么东西,它是关于创造的,是关于艺术的,某种程度上,我觉得这些可以称之为人类的意义,我不能说,我们在创造一种技术,来毁灭我们存在的意义,这么说肯定夸大其词,但我确实有在想,如果未来的某一天,AI 代替我们思考和创造,我们还剩下什么,所谓的 prompt 的艺术,其实也只是在 AI 还不够完善的时候,一种中间形态而已。AI 会释放人类的创造力,还是毁灭人类的创造力,好像还真的说不好,因为人虽然有无穷的创造力,但是也很懒。
生产力的无限提高,只有一个结果,就是不需要生产。
baye 是我敬仰的一位开发者,他也是著名的短信拦截应用熊猫吃短信的开发者,他前不久快速做了一个 iOS 的 app,实现了chatgpt 的第三方客户端,这成为了他数据上最成功的产品,但他在推文中写到「我一点感受不到兴奋和鼓舞。这是我做的最没技术含量或者说没有我个人烙印的产品了,就是一个 api wrapper 而已。我只感受到了热点的力量,没有感受到我的力量。这种感觉让我很是迷茫。」
 我知道的不少更资深的开发者,因为类似的原因,反而不如很多雄心勃勃的新手,AI 成为了一种武器,你只能选择使用或不使用,使用之后,个性和特点将被磨的更平,当然不会完全消失,但正因为 AI 的强大,边边角角的巧思显然会完全被那些绝佳的,生成的内容给盖过,以至于更难被人们注意到。
我不是想说技术的坏话,毫无疑问,底层大模型的开发者研究人员,是真正在推动人类向新的阶段迈进的,这是某种必然,但我们之后会迎来一个怎样的世界,我觉得说不好,我们也应该更谨慎一些。
小时候我常常幻想未来生活在一个科幻的世界,星际旅行,时空穿梭,瞬间移动,发射激光波,这个世界显然没有到来,但用另一种方式,现在的这个世界,似乎更加科幻。
这就是我那个下午想到的,然后我喝完咖啡,继续工作了。
我知道的不少更资深的开发者,因为类似的原因,反而不如很多雄心勃勃的新手,AI 成为了一种武器,你只能选择使用或不使用,使用之后,个性和特点将被磨的更平,当然不会完全消失,但正因为 AI 的强大,边边角角的巧思显然会完全被那些绝佳的,生成的内容给盖过,以至于更难被人们注意到。
我不是想说技术的坏话,毫无疑问,底层大模型的开发者研究人员,是真正在推动人类向新的阶段迈进的,这是某种必然,但我们之后会迎来一个怎样的世界,我觉得说不好,我们也应该更谨慎一些。
小时候我常常幻想未来生活在一个科幻的世界,星际旅行,时空穿梭,瞬间移动,发射激光波,这个世界显然没有到来,但用另一种方式,现在的这个世界,似乎更加科幻。
这就是我那个下午想到的,然后我喝完咖啡,继续工作了。
2023-01-20 11:09:36
最近几个月,以深度学习和神经网络为主导的 AI 技术正在席卷全球,人们发现 AI 会画画,AI 会写文章,会回答问题,还会解决问题,虽然诸如推荐算法,计算机视觉等 AI 技术其实早已改变我们生活了,但生成式 AI 所展现出的那种创造力,还是几乎让大多数人在惊叹于其神奇后,或多或少的感觉到了一丝隐忧,甚至恐惧。 我过去半年多都在做 6pen,但主要职责是产品,我对 AI 一窍不通,但一直以来,我对它的好奇从未减弱,大约 2 个月前,我下定决心,开始比较正式的学习深度学习和神经网络,并越来越被它的趣味和魅力吸引,于此同时,这个行业也在发生着快速和惊人的变化,我觉得这个时间节点非常微妙,它可能代表这一次转折,因此决定写这篇文章。 这篇文章会分成三个部分,第一部分是对深度学习的原理做简单的说明,这背后其实比很多人预想的要简单很多,了解原理有助于我们了解它的可能和局限,以及部分的实现技术去魅,然后,我会解释为什么我会觉得 AI 最先替代的,可能是 AI 工程师,最后,我会写一下对这个行业的个人拙见。
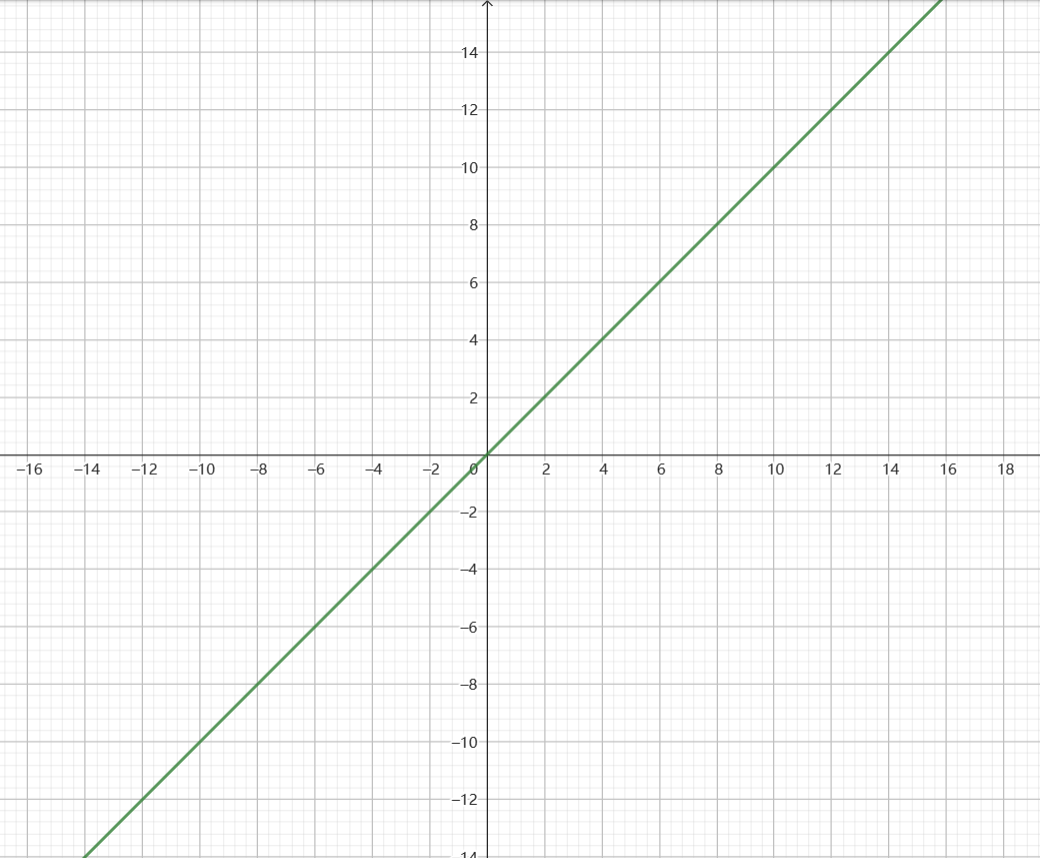 我们如果加个参数,例如 y = 2x,那么这条线就会发生变化,变陡一点,如果我们再加个参数,例如 y = 2x +4,那么这条线则会上移一点,看上去是这样
我们如果加个参数,例如 y = 2x,那么这条线就会发生变化,变陡一点,如果我们再加个参数,例如 y = 2x +4,那么这条线则会上移一点,看上去是这样
 这没有什么难的,但不管你信不信,这就是深度学习的原理了。
y=2x+4,可以看作是一个输入和输出都是一个数字,有两个参数的神经网络层,对于其中的 2 和 4 ,我们可以不断变化,来改变线的斜率和位置,这个过程就是学习。
学习的过程有点类似于用一种笨办法"解"方程式,数据集就是一些x和y的值,例如(x=1,y=6),(x=2,y=10),(x=3,y=14),开始训练之后,模型会随便设置这两个参数,比方说 y = 5x+102,这样一算,x=1的时候,y居然等于107,比数据集中的(x=1,y=6)大太多了,于是模型会把参数调小一点,比方说y=4x+50,这样再算,x=1的时候,y=45,还是太大了,于是模型再把参数调小一点,直到调到y=2x+1,结果发现,这样似乎算出来的y又太小了,于是模型再把参数调大一点。
这里面包含了神经网络深度学习的所有东西,首先是一个模型结构,我们已经设定成了y=ax+b,a和b是两个参数,然后模型会尝试不同的a和b,看差多少,这个看差多少的部分,叫做损失函数,然后,模型又会调整一下a和b的大小,负责调整的部分,则叫做优化器。
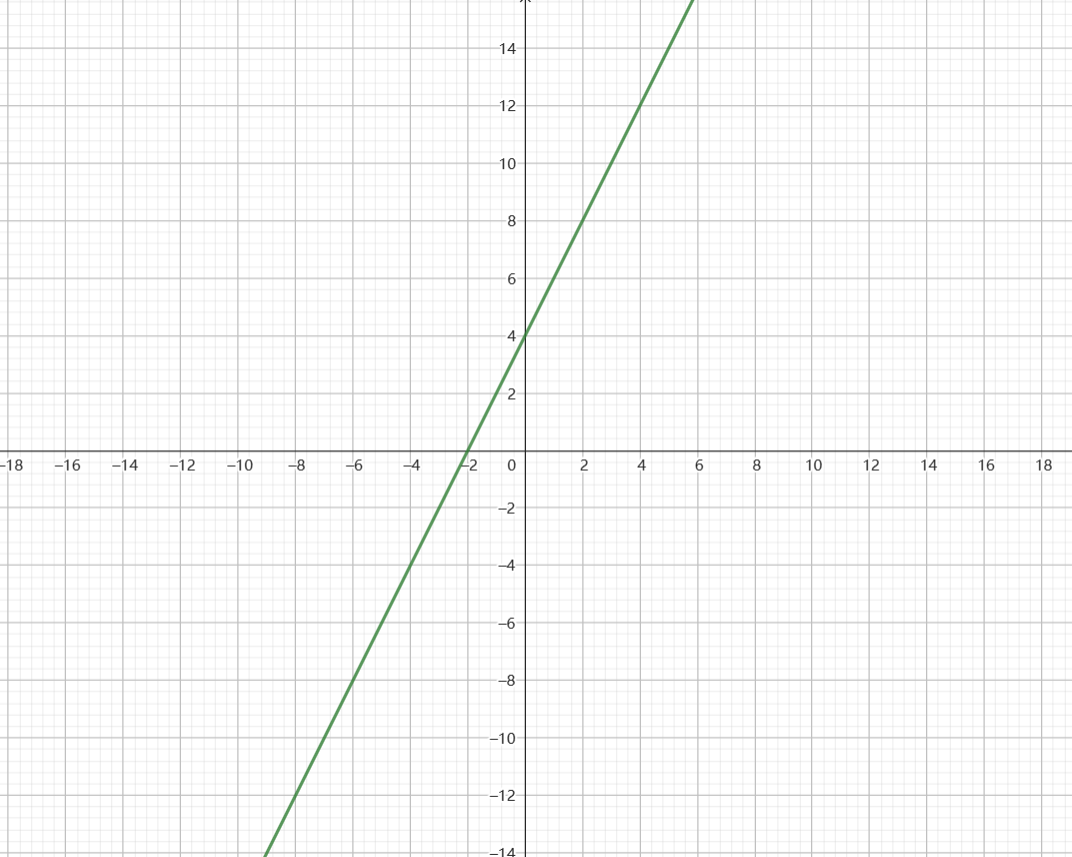
真实的神经网络,哪怕是最简单的层,也显然不会只是一个二元一次方程,它会比我们看到的更复杂一点,例如这样
这没有什么难的,但不管你信不信,这就是深度学习的原理了。
y=2x+4,可以看作是一个输入和输出都是一个数字,有两个参数的神经网络层,对于其中的 2 和 4 ,我们可以不断变化,来改变线的斜率和位置,这个过程就是学习。
学习的过程有点类似于用一种笨办法"解"方程式,数据集就是一些x和y的值,例如(x=1,y=6),(x=2,y=10),(x=3,y=14),开始训练之后,模型会随便设置这两个参数,比方说 y = 5x+102,这样一算,x=1的时候,y居然等于107,比数据集中的(x=1,y=6)大太多了,于是模型会把参数调小一点,比方说y=4x+50,这样再算,x=1的时候,y=45,还是太大了,于是模型再把参数调小一点,直到调到y=2x+1,结果发现,这样似乎算出来的y又太小了,于是模型再把参数调大一点。
这里面包含了神经网络深度学习的所有东西,首先是一个模型结构,我们已经设定成了y=ax+b,a和b是两个参数,然后模型会尝试不同的a和b,看差多少,这个看差多少的部分,叫做损失函数,然后,模型又会调整一下a和b的大小,负责调整的部分,则叫做优化器。
真实的神经网络,哪怕是最简单的层,也显然不会只是一个二元一次方程,它会比我们看到的更复杂一点,例如这样
 并且它具备很多层,每一层的输出,都将作为输出,传递给下一层,一个神经网络可能有50层,甚至更多,也可能只有几层,这取决于人们想用它解决什么问题。
但总的来说,这就是深度学习 神经网络的大致原理了。当我们的模型只有一层,且只有两个参数的 时候,我们只能得到一个数字,并且它很难有什么实际作用,但是当我们有上百层的模型结构,并且参数有1750亿的时候,事情就变得不一样了。
一个数据集中的样例可能是这样:输入是“你觉得老友记怎么样 ”,输出是“很棒,这是一部非常经典的美剧”,当然,这些句子都预先被某种方式转化成了一大堆数字,所以可以被各个方程式拿去计算,通过调节这一千多亿个参数,比方说第6428412456个参数,增加2.3,第5834728834个参数,减少9,当然这是我瞎写的,实际上有成千上万张显卡,用极其庞大的算力小心翼翼的调整这一千多亿个数字,试图让模型的输出,很接近我们给的数据集的输出。
同时,数据集也有数以亿计的样例,这些样例一次又一次的被模型用来调整自己的这一千多亿个参数,最后达到了一个比较好的效果,这样,在我们给一些数据集所没有的输入的时候,模型将有较大概率,能给一个看上去依然不错的输出,这个时候我们就说训练好了,或者用更专业的说法,收敛了。
我需要说明的是,事情远比以上的描述更加复杂,但原理确实就是这么简单。
我想我们不可能通过阅读几篇科普文章,就去干那些苦学了五六年才毕业的医生们做的工作,但我们至少要知道,生病的治疗方式可能是住院,补液,吃抗生素等等,而绝不会是吃水银,放血和跳大神。同样的,知道深度学习的大致原理,离着手从事相关工作,也有非常非常遥远的距离,但我们至少知道,噢原来是这么一回事。
并且它具备很多层,每一层的输出,都将作为输出,传递给下一层,一个神经网络可能有50层,甚至更多,也可能只有几层,这取决于人们想用它解决什么问题。
但总的来说,这就是深度学习 神经网络的大致原理了。当我们的模型只有一层,且只有两个参数的 时候,我们只能得到一个数字,并且它很难有什么实际作用,但是当我们有上百层的模型结构,并且参数有1750亿的时候,事情就变得不一样了。
一个数据集中的样例可能是这样:输入是“你觉得老友记怎么样 ”,输出是“很棒,这是一部非常经典的美剧”,当然,这些句子都预先被某种方式转化成了一大堆数字,所以可以被各个方程式拿去计算,通过调节这一千多亿个参数,比方说第6428412456个参数,增加2.3,第5834728834个参数,减少9,当然这是我瞎写的,实际上有成千上万张显卡,用极其庞大的算力小心翼翼的调整这一千多亿个数字,试图让模型的输出,很接近我们给的数据集的输出。
同时,数据集也有数以亿计的样例,这些样例一次又一次的被模型用来调整自己的这一千多亿个参数,最后达到了一个比较好的效果,这样,在我们给一些数据集所没有的输入的时候,模型将有较大概率,能给一个看上去依然不错的输出,这个时候我们就说训练好了,或者用更专业的说法,收敛了。
我需要说明的是,事情远比以上的描述更加复杂,但原理确实就是这么简单。
我想我们不可能通过阅读几篇科普文章,就去干那些苦学了五六年才毕业的医生们做的工作,但我们至少要知道,生病的治疗方式可能是住院,补液,吃抗生素等等,而绝不会是吃水银,放血和跳大神。同样的,知道深度学习的大致原理,离着手从事相关工作,也有非常非常遥远的距离,但我们至少知道,噢原来是这么一回事。
2022-11-27 22:29:08
我所在的小区,在11月19日突然发了一则公告,大意是因为小区内有阳性病例,所以要封锁5天,只进不出,同时整个小区全部变成高风险,五天后,也就是11月24日,封锁没有解除的迹象,小区群内流传着一张新的通告,通告中写「因为疫情形势非常严峻,24日至27日实施为期三天的临时管控」,但这则通告的落款并非任何部门,是小区名字后加一个「疫情防控办公室」,显得似乎有一些可疑,但无疑的是,我们在第一个六天后,还将面临至少三天的新的封控。
 在封锁的这几天内,每栋楼楼下都有两个穿白色防护服的工作人员,24小时都有这么两个人在楼下,我观察到,他们既非医护人员,也不是警务人员,其中一个是一个大爷,喜欢喝茶,喜欢抽烟,把一楼电梯厅弄的烟味很重,另一个是个年轻点的人,偶尔会把防护服的帽子脱到脑后,去门口吹冷风。
封控的这几天,我偶尔会下楼扔垃圾,拿买的菜,菜会由另一些穿白色防护服的工作人员从小区门口拿到每栋楼里,严格意义上来说,我拿菜是不出楼栋的,但扔垃圾还是要出去,所以我每天还是会出去透口气。
我从美团或永辉线上买菜,前两天的时候,还可以随时买,不过要五六个小时之后才会送到,第三天后,除非在凌晨12点刚过的时候立刻下单,否则就无法下单了,因为只需要几分钟,就会将这些平台未来1-2天的运力全部占满。
我定好闹钟,连续2个晚上在12点刚过的时候下单了一堆食材,全部记录到囤饭饭里,然后终于有了一些安全感。
在封锁的这几天内,每栋楼楼下都有两个穿白色防护服的工作人员,24小时都有这么两个人在楼下,我观察到,他们既非医护人员,也不是警务人员,其中一个是一个大爷,喜欢喝茶,喜欢抽烟,把一楼电梯厅弄的烟味很重,另一个是个年轻点的人,偶尔会把防护服的帽子脱到脑后,去门口吹冷风。
封控的这几天,我偶尔会下楼扔垃圾,拿买的菜,菜会由另一些穿白色防护服的工作人员从小区门口拿到每栋楼里,严格意义上来说,我拿菜是不出楼栋的,但扔垃圾还是要出去,所以我每天还是会出去透口气。
我从美团或永辉线上买菜,前两天的时候,还可以随时买,不过要五六个小时之后才会送到,第三天后,除非在凌晨12点刚过的时候立刻下单,否则就无法下单了,因为只需要几分钟,就会将这些平台未来1-2天的运力全部占满。
我定好闹钟,连续2个晚上在12点刚过的时候下单了一堆食材,全部记录到囤饭饭里,然后终于有了一些安全感。
 26号,也就是原定三天封控的前一天,没有任何动静,中午我在小区群里看到,有人隐晦的发言,表示下午两点,大家可以去小区门口,我们合理的表达自己的诉求,争取解封,据此而新建立的一个微信群,名字都叫「合理诉求」。
26号,也就是原定三天封控的前一天,没有任何动静,中午我在小区群里看到,有人隐晦的发言,表示下午两点,大家可以去小区门口,我们合理的表达自己的诉求,争取解封,据此而新建立的一个微信群,名字都叫「合理诉求」。
 一点五十,我下楼扔垃圾,扔完垃圾我有点想直接往门口走,但眼瞅着两个白卫兵似乎在远处看我,我怂了一下,于是绕到楼后面,从楼后的小路走到了小区门口。
小区门口零星的站了几个人,在我走向他们的时候,周边的楼栋高层不时传出解封的吼声,以及一两声别的什么听不出含义的吼叫,今天的阳光比前几天更温热一些,空气也很好,但有一种山雨欲来风满楼的感觉。
离门口很近的一个楼,楼门口的门被关上了,但里面挤满了人,两个白卫兵把守着门口,不让里面的人出来,我旁边一个女生走过去大声问他们,你们想出来吗?他们不让你们出来吗?我和几个别的外面的人一起走到那个楼的门口,外面的人大声对立面的人说,出来,出来,出来。
一点五十,我下楼扔垃圾,扔完垃圾我有点想直接往门口走,但眼瞅着两个白卫兵似乎在远处看我,我怂了一下,于是绕到楼后面,从楼后的小路走到了小区门口。
小区门口零星的站了几个人,在我走向他们的时候,周边的楼栋高层不时传出解封的吼声,以及一两声别的什么听不出含义的吼叫,今天的阳光比前几天更温热一些,空气也很好,但有一种山雨欲来风满楼的感觉。
离门口很近的一个楼,楼门口的门被关上了,但里面挤满了人,两个白卫兵把守着门口,不让里面的人出来,我旁边一个女生走过去大声问他们,你们想出来吗?他们不让你们出来吗?我和几个别的外面的人一起走到那个楼的门口,外面的人大声对立面的人说,出来,出来,出来。
 里面的人在试图推开门,没料到其中一个白卫兵居然直接用一块木板,把门闸上了,他的做法引起了一阵更强烈的不满,但与此同时,居然有很多人,从另一个门出来了,大家又发出一阵欢呼,我回过头看原来的那扇门,居然也神奇的打开了,里面的人也鱼贯而出。
再加上其他楼里出来的人,此时外面大概站了二三十个人。一篇文章二三十的阅读量很低,但二三十个人站在一起,还是很有分量,大家聚往小区门口,那里有一道栅栏,栅栏外是几辆警车。
里面的人在试图推开门,没料到其中一个白卫兵居然直接用一块木板,把门闸上了,他的做法引起了一阵更强烈的不满,但与此同时,居然有很多人,从另一个门出来了,大家又发出一阵欢呼,我回过头看原来的那扇门,居然也神奇的打开了,里面的人也鱼贯而出。
再加上其他楼里出来的人,此时外面大概站了二三十个人。一篇文章二三十的阅读量很低,但二三十个人站在一起,还是很有分量,大家聚往小区门口,那里有一道栅栏,栅栏外是几辆警车。
 站定后人群开始高呼,解封,解封,解封,除了我们这群在外面的人,楼栋高层也传出同样的喊声,我身边一个女生抬头对上面叫道,下来,下来,下来,又有一个嗓门大的男生跟着喊,下来,人多力量大。
我们小区分为南北两个区,中间有一条小巷隔开,我在北区,和我们隔街相望,南区也聚集了很多人,挤在他们那一侧的门口,而中间则是几辆警车,几位警察,以及穿防护服的人,大概有十多个人。
在我们高喊一阵儿之后,有个警察过来跟我们对话,他是附近派出所的所长,我们这边拿出二十条之类的规定据理力争,对方说情况他们已经了解,相关部门的领导会在2点半过来,跟小区代表对话,大家可以回家了,当然没人同意回家,几个嗓门大的喊,我们不回去,就在这解决,众人附和。
此时是两点十分左右,我回头看了一眼,身后的人多了很多,大概七八十个,再加上南区,可能有接近两百人了。
两点二十五的时候,所谓的领导还没有来,众人时不时又叫一遍遍的解封,突然,南区出现一阵骚动,南区隔离的蓝色铁皮发出咚的一声,所有人都为之叫好,然后又发出咚的一声,大家又叫好,随之铁皮出现了一个弯曲的缺口,然后被很多双手和脚推的更加摇摇欲坠,然后砰的一声,整个铁皮都倒了,大家爆发出巨大的欢呼,南区的人流随之涌出,我们北区这一边,也开始推开栅栏往外走,两股人群在小巷中央,汇合了。
站定后人群开始高呼,解封,解封,解封,除了我们这群在外面的人,楼栋高层也传出同样的喊声,我身边一个女生抬头对上面叫道,下来,下来,下来,又有一个嗓门大的男生跟着喊,下来,人多力量大。
我们小区分为南北两个区,中间有一条小巷隔开,我在北区,和我们隔街相望,南区也聚集了很多人,挤在他们那一侧的门口,而中间则是几辆警车,几位警察,以及穿防护服的人,大概有十多个人。
在我们高喊一阵儿之后,有个警察过来跟我们对话,他是附近派出所的所长,我们这边拿出二十条之类的规定据理力争,对方说情况他们已经了解,相关部门的领导会在2点半过来,跟小区代表对话,大家可以回家了,当然没人同意回家,几个嗓门大的喊,我们不回去,就在这解决,众人附和。
此时是两点十分左右,我回头看了一眼,身后的人多了很多,大概七八十个,再加上南区,可能有接近两百人了。
两点二十五的时候,所谓的领导还没有来,众人时不时又叫一遍遍的解封,突然,南区出现一阵骚动,南区隔离的蓝色铁皮发出咚的一声,所有人都为之叫好,然后又发出咚的一声,大家又叫好,随之铁皮出现了一个弯曲的缺口,然后被很多双手和脚推的更加摇摇欲坠,然后砰的一声,整个铁皮都倒了,大家爆发出巨大的欢呼,南区的人流随之涌出,我们北区这一边,也开始推开栅栏往外走,两股人群在小巷中央,汇合了。
 汇合的人群发出出更大的声音,这时候,不知名的领导来了。
领导穿蓝色羽绒服,有一点年纪了,头发白了一部分,他和派出所所长商量了几句,然后对我们说,最新的通知是,除了有阳性的5栋楼:XXX,XXX,其他的楼,大家回去测一遍核酸,然后明天解封。
这是我们第一次知道,阳性所在的楼具体是在哪几个楼,同时也知道了,原来剩下的十几个楼栋,其实都在遭受无妄之灾,按照二十条的规定,没有阳性的楼栋,不应该被划为高风险,但这个小区二十几个楼,在过去都被划为高风险,且完全被封控。
但大家并不满意,因为承诺是没有任何保证的,有人喊,不回去,不做核酸,解封。
事态到这里有点僵持住了,我感觉他们也不敢也没有能力直接告诉我们可以现在解封,于是又开始商量,人群等待了十几分钟,可能更久,大家按耐不住,有人大叫了一声,起~来~,然后人群开始齐声唱起了国歌,唱完后似乎得到了某种力量,开始往前走,我们走一点,他们就后退一点,这样一点点走到了小巷最外侧的那道最后的栅栏。
在往前走的时候,两侧的围墙,以及更远处的楼栋的高层阳台上,也布满了人,有人对他们喊,出来跟我们一起,你们愿意做一辈子的懦夫,还是十分钟的英雄?这句话可能过于中二了,以至于没有人回应,但随即有个洪亮的声音从不知道哪里发出,我们不想做英雄,只想做一个自由的普通人。
警察和其他工作人员并没有阻挡人群的向前,一退再退,人群越过最后的那道栅栏,眼看有游行的趋势,有谨慎的人赶紧喊大家,差不多就回来,别走太远了,我们的诉求是解封。
有关部门的领导感觉下定了某种决心,对大家说,我现在就调人!我现在就调人!现在就做核酸,做完明天就解封。
一部分人得到这个较为确凿的答复,已经比较满意,还有一部分人坚持,不做核酸,直接解封。
但人群在这个时候开始有了分化,并且开始互相劝说,半小时后,一辆考斯特开过来,下来了一些医护人员,走到小区里开始支起了简易核酸点,虽然还有一些零星的不满,还有一部分人继续去了居委会,但最后大家也基本开始去排队,做了核酸。
第二天,我睡醒后立马打开手机看消息,小区内基本已经互通,但小巷最外侧的栅栏还在,但出入已经不会有人强行阻拦了,有的人早上已经去外面买了早饭回来。
汇合的人群发出出更大的声音,这时候,不知名的领导来了。
领导穿蓝色羽绒服,有一点年纪了,头发白了一部分,他和派出所所长商量了几句,然后对我们说,最新的通知是,除了有阳性的5栋楼:XXX,XXX,其他的楼,大家回去测一遍核酸,然后明天解封。
这是我们第一次知道,阳性所在的楼具体是在哪几个楼,同时也知道了,原来剩下的十几个楼栋,其实都在遭受无妄之灾,按照二十条的规定,没有阳性的楼栋,不应该被划为高风险,但这个小区二十几个楼,在过去都被划为高风险,且完全被封控。
但大家并不满意,因为承诺是没有任何保证的,有人喊,不回去,不做核酸,解封。
事态到这里有点僵持住了,我感觉他们也不敢也没有能力直接告诉我们可以现在解封,于是又开始商量,人群等待了十几分钟,可能更久,大家按耐不住,有人大叫了一声,起~来~,然后人群开始齐声唱起了国歌,唱完后似乎得到了某种力量,开始往前走,我们走一点,他们就后退一点,这样一点点走到了小巷最外侧的那道最后的栅栏。
在往前走的时候,两侧的围墙,以及更远处的楼栋的高层阳台上,也布满了人,有人对他们喊,出来跟我们一起,你们愿意做一辈子的懦夫,还是十分钟的英雄?这句话可能过于中二了,以至于没有人回应,但随即有个洪亮的声音从不知道哪里发出,我们不想做英雄,只想做一个自由的普通人。
警察和其他工作人员并没有阻挡人群的向前,一退再退,人群越过最后的那道栅栏,眼看有游行的趋势,有谨慎的人赶紧喊大家,差不多就回来,别走太远了,我们的诉求是解封。
有关部门的领导感觉下定了某种决心,对大家说,我现在就调人!我现在就调人!现在就做核酸,做完明天就解封。
一部分人得到这个较为确凿的答复,已经比较满意,还有一部分人坚持,不做核酸,直接解封。
但人群在这个时候开始有了分化,并且开始互相劝说,半小时后,一辆考斯特开过来,下来了一些医护人员,走到小区里开始支起了简易核酸点,虽然还有一些零星的不满,还有一部分人继续去了居委会,但最后大家也基本开始去排队,做了核酸。
第二天,我睡醒后立马打开手机看消息,小区内基本已经互通,但小巷最外侧的栅栏还在,但出入已经不会有人强行阻拦了,有的人早上已经去外面买了早饭回来。
 下午三点,我骑车出去,和大家说的一样,栅栏还在,有一个似乎是保安的人在看守,我直接把栅栏推开,他没有做任何表示,然后我骑到了附近的超市,买了一些食材,本来还想去瑞幸买一杯咖啡,但周围的瑞幸和别的咖啡店,也都关门了,我去了711,买了一杯冰美式,然后骑车回了家。
下午三点,我骑车出去,和大家说的一样,栅栏还在,有一个似乎是保安的人在看守,我直接把栅栏推开,他没有做任何表示,然后我骑到了附近的超市,买了一些食材,本来还想去瑞幸买一杯咖啡,但周围的瑞幸和别的咖啡店,也都关门了,我去了711,买了一杯冰美式,然后骑车回了家。
 到家后,大概五点,我看到群里有人发了图片,最外层的栅栏已经被正式移走,几乎所有楼栋也都被贴上了「解除封控通知」,车辆开始出入,小区终于,正式解封了。
到家后,大概五点,我看到群里有人发了图片,最外层的栅栏已经被正式移走,几乎所有楼栋也都被贴上了「解除封控通知」,车辆开始出入,小区终于,正式解封了。
 回顾这次的基于合理诉求的解封活动,我依然觉得很值得被记录,我尤其记得在最开始,有两个嗓门大的女生,她们发出了第一声呼吁,得到了越来越多的响应,而在后来,她们的声音依然深刻在我身边响亮,另外我还注意,在人群行动时,有一对情侣,女生想往前走,被男生拉住了,他们互相说了几句,然后又一起往前走了。
坦白来说,我们这些聚集起来的人,其实是一帮乌合之众,没有组织或纪律,甚至没有牵头人或代表,诉求也不尽相同,经常出现前的人在对话,后面的人就瞎叫,结果搞的对话进行不下去的情况,但所有人的最底层的诉求是一致的,那就是要活下去,有尊严的活下去。
我们肯定不至完全活不下去,但也有人吃了四天泡面了,也有人一天只吃一顿饭,也有人抢菜经常抢不到,因此焦虑的睡不着,所有的大道理,比不过吃饭事大。
换个角度来看,即便我们是乌合之众,即便我们乱糟糟,乌泱泱的,许多人抱有勇气,另一些人则只是观望,也有怂的,焉儿的,但人群聚在一起,就真的有强大的力量,我们争取来了合法合规的解封,也拿回了吃饭的权利,有尊严的活着的权利,在我们之前,周边就有别的零星的小区,也用这种方式得到了解封,在我们之后,还有更多小区也会得到本来就不应该剥夺的自由。
当然有运气的成分,我甚至觉得那个派出所所长对我们是能够有一定程度的理解的,最激烈的冲突也未升级成真正的肢体对抗,而现在依然不知道身份的那个领导,也算是说话算话,把自由,虽然这是我们本应该有的,还给了我们。
但不管运气的成分,如果误以为我们这样的一群人不用拿出勇气,魄力和决心,就可以轻易取得了最后的结果,那才是真正的大错特错,在解封的第二天,小区群里果然出现了一种言论「去闹什么事,增加了危险,反正都要解封的,这不就解了吗?」
这是一定会有的言论,也一定会有人坐享其成却过河拆桥,但这不重要,重要的是总会有一群人,这群人始终会站出来,我们要和他们站在一起。
回顾这次的基于合理诉求的解封活动,我依然觉得很值得被记录,我尤其记得在最开始,有两个嗓门大的女生,她们发出了第一声呼吁,得到了越来越多的响应,而在后来,她们的声音依然深刻在我身边响亮,另外我还注意,在人群行动时,有一对情侣,女生想往前走,被男生拉住了,他们互相说了几句,然后又一起往前走了。
坦白来说,我们这些聚集起来的人,其实是一帮乌合之众,没有组织或纪律,甚至没有牵头人或代表,诉求也不尽相同,经常出现前的人在对话,后面的人就瞎叫,结果搞的对话进行不下去的情况,但所有人的最底层的诉求是一致的,那就是要活下去,有尊严的活下去。
我们肯定不至完全活不下去,但也有人吃了四天泡面了,也有人一天只吃一顿饭,也有人抢菜经常抢不到,因此焦虑的睡不着,所有的大道理,比不过吃饭事大。
换个角度来看,即便我们是乌合之众,即便我们乱糟糟,乌泱泱的,许多人抱有勇气,另一些人则只是观望,也有怂的,焉儿的,但人群聚在一起,就真的有强大的力量,我们争取来了合法合规的解封,也拿回了吃饭的权利,有尊严的活着的权利,在我们之前,周边就有别的零星的小区,也用这种方式得到了解封,在我们之后,还有更多小区也会得到本来就不应该剥夺的自由。
当然有运气的成分,我甚至觉得那个派出所所长对我们是能够有一定程度的理解的,最激烈的冲突也未升级成真正的肢体对抗,而现在依然不知道身份的那个领导,也算是说话算话,把自由,虽然这是我们本应该有的,还给了我们。
但不管运气的成分,如果误以为我们这样的一群人不用拿出勇气,魄力和决心,就可以轻易取得了最后的结果,那才是真正的大错特错,在解封的第二天,小区群里果然出现了一种言论「去闹什么事,增加了危险,反正都要解封的,这不就解了吗?」
这是一定会有的言论,也一定会有人坐享其成却过河拆桥,但这不重要,重要的是总会有一群人,这群人始终会站出来,我们要和他们站在一起。
2022-11-24 22:40:16
三年前写过一篇文章「我创业的这三年」,三年又三年,好家伙,今年已经是六年了。
开头的三年,我做的很差,我至今依然没有洗清某种学生气,或者在某些时候不合时宜的对世界的天真看法,但那时候问题显然严重得多。
2016年,我从大学来到北京,我花了一年多的时间,才发现我一开始的创业方向错的离谱,然后又再花了一年多,才找到相对正确的方向,对于大多数情况较好的创业来说,这是人家的起点,而我花了三年才达到。
2019年,我开始全身心投入面包多这个产品,也就是上一篇三年总结中的「帮助创造者获得收入,帮助他们到达更远的地方」,那篇总结写在面包多上线的第四个月,我虽然已经相对谨慎,但还是没注意到文章里有一口毒奶,我这么写当时的面包多:
「也在过去的四个月,每个月都保持了 200% 以上的增长,在某种程度上,我可以说,我们终于开始揭开一个「拿的出手」的产品的面纱了」
文章发出去之后的下个月,面包多增长骤停,其实这也不难理解,当每月流水只有一两万的时候,增长个 200% 甚至 500% 都很容易,假如说身上只有 1 毛钱,那在路上捡了五块钱,都算是增长 5000% 了,面包多比1毛钱或5块钱好一点,上线四个月后月流水开始能有五六万了,这意味着每天有差不多两千块。
很惭愧,我拿了几百万的天使投资,虽然开始做面包多的时候已经所剩不多,但也好歹还有超过10人的团队,结果搞出来的东西,就是一天 2 千块的流水,并且我们赚的还只有 5% ,也就是 100 块。
好在那段时间我不咋写文章,开始更加积极的做产品更新和一些有意思的创新,然后数据开始继续增长。
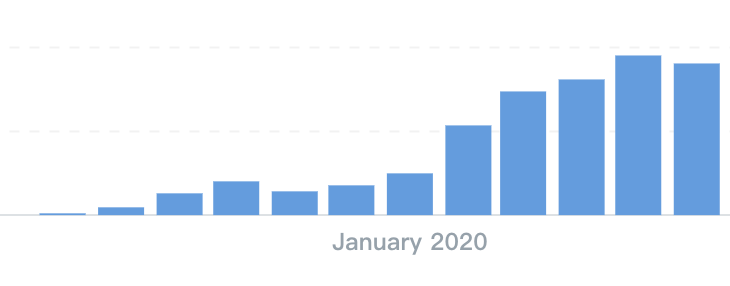 一方面我在用很多办法削减支出,一方面我们的收入也在增加,最终我期待的事情在 2020 年底的时候发生了,那就是我们靠自己的赚的钱,可以够团队的成本,也就是达到了收支平衡。这不算是特别值得庆祝的事情,因为那时候团队已经被我砍到四个人了,再砍下去,就可能无法维持最基础的产品运作和更新了,但不砍的话,账上的钱其实很快就会见底,我最终在2020年的悬崖边缘,勒住了马。
大多数创业者是在有足够的积累,广阔的资源,坚定的想法,然后投身其中的,而在我前三年的创业中,我对这些几乎一无所有,对团队管理,更长远的规划,市场和竞争也几乎一无所知,只是埋头想做点啥东西,这就好比玩游戏,我本来应该先从新手教程学起,按O攻击,按X跳跃,但我却突然跑到最终 boss 面前,然而又因为卡了一个 bug,让 boss 一直没把我打死,这样苟过了三年。
走这一段弯路,没有从一开始直接杀入创业最核心的那个部分,虽然是我的不幸,但从整个过程来看,也可以看作是一种幸运了,当三年后,我因为面包多重新面对真正的市场和行业的时候,虽然趔趄但不至于倒下,这里的弯路也有一些作用。
我经历过的最激烈的竞争和最凶猛的攻击,都是在面包多增长最好的那段时间,我们被诬陷,被举报,被投毒(指在产品里故意发布违规内容,倒还不是用氰化物这种),也被人误解和扭曲,不道德的竞争手段就更多了,那些坐在办公室的凉风,MacBook,星巴克,那些逗趣的行业黑话和中英夹杂的表达,那些大厂的履历和背景,那些时髦光鲜的峰会座谈,最终还是会统统变成丛林法则,弱肉强食,欺善怕恶,唯利是图。
我其实很长时间都无法理解,我一直以为,互联网,应当不至于此,但确实是至的,这和互联网没有关系,这是人性。当然,不赚钱和特别特别赚钱的事情,可能情况会好很多。
我大学挂科很多的原因是我不作弊,不作弊的原因并非我是什么大好人,而是因为我见到身边的人都在作弊,这使我更厌恶作弊,我也不是什么正人君子,但如果见到的恶太多,我则会嫉恶如仇,我怀疑世界上可能有一种人就喜欢在好人堆里当个蔫坏的人,而在坏人堆里却一定要当好人,这种人朋友肯定不会太多,但活得应该比较有意思。
这里就回到了最初也是最终的问题,那就是为什么我要选择创业,而不是打工或者啃老,首先我要排除啃老,因为我过意不去,我爸妈也不会很乐意,其次是打工,我短暂的试过可能20天到1个月,但发现,如果我每天都在做一个我不想做的事情,或者无法把时间花在我想做的事情上面,我简直度日如年。
于是,做自己想做的事情,就成为了我唯一舒服的生活方式,而这种方式加入赚钱的部分,我们就称之为创业,后来又会加一些别的东西,比如股东,责任,投融资,回报,这些东西让事情变得更复杂,但总的来说还是主要做我想做的事情,或者说,保有能做我想做的事情的能力。
与其思考创业的目的,不如思考人生的目的,创业的目的可以用赚钱来逃避,人生则困难一些,但两者在某种程度上是一致的,当一个创业者无法把人生的目的和创业的目的进行某种关联的时候,就我经验来看,其人生和创业可能都会出问题。
这倒不是说,我们就决不做不愿意做的事情了,而是始终要清楚,做不愿意做的事情,只是为了达到目的,但不是目的本身,不愿意做的事情做多了,可能会从手段变成目的本身,那就大事不妙了。
最近几个月,我又无意中进入了一个极卷的行业,当我们 6 月底上线 6pen 这个 AI 绘画工具的时候,我只是觉得文本变成图片这件事很好玩,且 dalle2 和 midjourney 的内测很让人烦,于是想做一个没有门槛的小工具,但随着 8 月底 stable diffsuion 的开源,进入门槛瞬间降低,然后我们就在大约 1 个月内出现了大概 30 个竞品,未来可能还会有 300 个。
相较于其他 AI 绘画工具的野路子:完全不遵守开源模型的规定,欺骗用户,套壳和各种抄袭,极其低劣的推广方式,6pen 像是一朵白莲花,甚至我都有点烦了,为什么我们就不能像他们一样搞搞呢,用户哪里会在意你用了泄漏的 novelai 模型或者把 stable diffusion 说成是自研。我可以找到很多理由,例如我们要做长期价值,我们要通过创新来获得优势,但最重要的原因就是,这么做没意思。
我花了这么多时间和功夫,才能够做我想做的事情,如果现在又要做没意思的事情,那还有什么意思。
当然,我们确实会做很多创新,也会完全和这些同质化严重的大量产品拉开足够大的差距,但最重要的原因还是,我不想做没意思的事情。
我希望我能做成,因为这有两个可能性,要么是世界更本质的东西其实还是我希望的样子,要么是我让世界变得更像是我希望的样子一点,无论哪一种,这总是让人开心的。
我有一个比我成功很多的创业的朋友,他有一天深夜给我发了一条消息,说「我做了一次坏人」,我没有问,他也没有继续说,我认为做一次坏人是极有可能的,尤其是对创业者而言,但我们应该只做一次坏人,而不要彻底成为一个坏人。
第六年,我比之前走的稍微更近了一步,我没有发财或者成功,离做大做强也依然很有距离,但我看到更多这个世界的样子,也更深入的看到了许多人心和人性,我依然保有最开始的某种状态,并依然在追求同样的东西,我想这应该是很幸运的事情。
六年已经超过了中国中小企业的平均存续时间,这并不是一件容易的事情,但更重要的原因不是我做的有多好,事实上我有很多时刻,那些时刻其实解散或关闭公司是理论上更正确的选择,我只是基于个人主观的原因持续了下来,结果怎么样还不好说,但好歹我确实还没下牌桌。
虽然我换过多个方向,但公司主体没有变过,所有老股东也还都在这里,与 2016 年初冬时我注册的那家公司的价值相比,至少在纸面的估值上,它提高了 60 倍,当我意识到这一点的时候其实也挺吃惊的,这是我学到的另一件事,无论做的有多差,但只要一直做,就会有或多或少的沉淀,经年累月之下,可能也会成为可观的积累,这也是某一种复利。
六年时间对应一个完整的小学,从一年级到六年级,可能是人生中变化最大的六年,小学毕业的二十年后,我可以算作重新体验了这样一次巨大的变化。
接下来,我进入创业的初中了。
一方面我在用很多办法削减支出,一方面我们的收入也在增加,最终我期待的事情在 2020 年底的时候发生了,那就是我们靠自己的赚的钱,可以够团队的成本,也就是达到了收支平衡。这不算是特别值得庆祝的事情,因为那时候团队已经被我砍到四个人了,再砍下去,就可能无法维持最基础的产品运作和更新了,但不砍的话,账上的钱其实很快就会见底,我最终在2020年的悬崖边缘,勒住了马。
大多数创业者是在有足够的积累,广阔的资源,坚定的想法,然后投身其中的,而在我前三年的创业中,我对这些几乎一无所有,对团队管理,更长远的规划,市场和竞争也几乎一无所知,只是埋头想做点啥东西,这就好比玩游戏,我本来应该先从新手教程学起,按O攻击,按X跳跃,但我却突然跑到最终 boss 面前,然而又因为卡了一个 bug,让 boss 一直没把我打死,这样苟过了三年。
走这一段弯路,没有从一开始直接杀入创业最核心的那个部分,虽然是我的不幸,但从整个过程来看,也可以看作是一种幸运了,当三年后,我因为面包多重新面对真正的市场和行业的时候,虽然趔趄但不至于倒下,这里的弯路也有一些作用。
我经历过的最激烈的竞争和最凶猛的攻击,都是在面包多增长最好的那段时间,我们被诬陷,被举报,被投毒(指在产品里故意发布违规内容,倒还不是用氰化物这种),也被人误解和扭曲,不道德的竞争手段就更多了,那些坐在办公室的凉风,MacBook,星巴克,那些逗趣的行业黑话和中英夹杂的表达,那些大厂的履历和背景,那些时髦光鲜的峰会座谈,最终还是会统统变成丛林法则,弱肉强食,欺善怕恶,唯利是图。
我其实很长时间都无法理解,我一直以为,互联网,应当不至于此,但确实是至的,这和互联网没有关系,这是人性。当然,不赚钱和特别特别赚钱的事情,可能情况会好很多。
我大学挂科很多的原因是我不作弊,不作弊的原因并非我是什么大好人,而是因为我见到身边的人都在作弊,这使我更厌恶作弊,我也不是什么正人君子,但如果见到的恶太多,我则会嫉恶如仇,我怀疑世界上可能有一种人就喜欢在好人堆里当个蔫坏的人,而在坏人堆里却一定要当好人,这种人朋友肯定不会太多,但活得应该比较有意思。
这里就回到了最初也是最终的问题,那就是为什么我要选择创业,而不是打工或者啃老,首先我要排除啃老,因为我过意不去,我爸妈也不会很乐意,其次是打工,我短暂的试过可能20天到1个月,但发现,如果我每天都在做一个我不想做的事情,或者无法把时间花在我想做的事情上面,我简直度日如年。
于是,做自己想做的事情,就成为了我唯一舒服的生活方式,而这种方式加入赚钱的部分,我们就称之为创业,后来又会加一些别的东西,比如股东,责任,投融资,回报,这些东西让事情变得更复杂,但总的来说还是主要做我想做的事情,或者说,保有能做我想做的事情的能力。
与其思考创业的目的,不如思考人生的目的,创业的目的可以用赚钱来逃避,人生则困难一些,但两者在某种程度上是一致的,当一个创业者无法把人生的目的和创业的目的进行某种关联的时候,就我经验来看,其人生和创业可能都会出问题。
这倒不是说,我们就决不做不愿意做的事情了,而是始终要清楚,做不愿意做的事情,只是为了达到目的,但不是目的本身,不愿意做的事情做多了,可能会从手段变成目的本身,那就大事不妙了。
最近几个月,我又无意中进入了一个极卷的行业,当我们 6 月底上线 6pen 这个 AI 绘画工具的时候,我只是觉得文本变成图片这件事很好玩,且 dalle2 和 midjourney 的内测很让人烦,于是想做一个没有门槛的小工具,但随着 8 月底 stable diffsuion 的开源,进入门槛瞬间降低,然后我们就在大约 1 个月内出现了大概 30 个竞品,未来可能还会有 300 个。
相较于其他 AI 绘画工具的野路子:完全不遵守开源模型的规定,欺骗用户,套壳和各种抄袭,极其低劣的推广方式,6pen 像是一朵白莲花,甚至我都有点烦了,为什么我们就不能像他们一样搞搞呢,用户哪里会在意你用了泄漏的 novelai 模型或者把 stable diffusion 说成是自研。我可以找到很多理由,例如我们要做长期价值,我们要通过创新来获得优势,但最重要的原因就是,这么做没意思。
我花了这么多时间和功夫,才能够做我想做的事情,如果现在又要做没意思的事情,那还有什么意思。
当然,我们确实会做很多创新,也会完全和这些同质化严重的大量产品拉开足够大的差距,但最重要的原因还是,我不想做没意思的事情。
我希望我能做成,因为这有两个可能性,要么是世界更本质的东西其实还是我希望的样子,要么是我让世界变得更像是我希望的样子一点,无论哪一种,这总是让人开心的。
我有一个比我成功很多的创业的朋友,他有一天深夜给我发了一条消息,说「我做了一次坏人」,我没有问,他也没有继续说,我认为做一次坏人是极有可能的,尤其是对创业者而言,但我们应该只做一次坏人,而不要彻底成为一个坏人。
第六年,我比之前走的稍微更近了一步,我没有发财或者成功,离做大做强也依然很有距离,但我看到更多这个世界的样子,也更深入的看到了许多人心和人性,我依然保有最开始的某种状态,并依然在追求同样的东西,我想这应该是很幸运的事情。
六年已经超过了中国中小企业的平均存续时间,这并不是一件容易的事情,但更重要的原因不是我做的有多好,事实上我有很多时刻,那些时刻其实解散或关闭公司是理论上更正确的选择,我只是基于个人主观的原因持续了下来,结果怎么样还不好说,但好歹我确实还没下牌桌。
虽然我换过多个方向,但公司主体没有变过,所有老股东也还都在这里,与 2016 年初冬时我注册的那家公司的价值相比,至少在纸面的估值上,它提高了 60 倍,当我意识到这一点的时候其实也挺吃惊的,这是我学到的另一件事,无论做的有多差,但只要一直做,就会有或多或少的沉淀,经年累月之下,可能也会成为可观的积累,这也是某一种复利。
六年时间对应一个完整的小学,从一年级到六年级,可能是人生中变化最大的六年,小学毕业的二十年后,我可以算作重新体验了这样一次巨大的变化。
接下来,我进入创业的初中了。